
A New BI Vector of Real-time and AI-enabled Anomaly Detection
Failing to adopt new BI paradigms can leave your business among the lagers in the market. In fact, 95% of businesses now view big data and real-time analytics capabilities as a necessity to keep up and/or outpace the competition. Anomaly and fraud detection are two particular areas where tech innovations have become an absolute necessity.
Why Manual Anomaly Detection is No Longer Working for Businesses
Anomalies – irregular or unusual data patterns in complex environments – can relate to some issues and cause massive havoc when left unattended.
- Lagging application performance can cost your business major revenues. For Amazon, a one-second delay can equate to a $1.6 billion decrease in annual sales.
- Banking fraud is rampant: 50% of organizations have experienced an increase in fraud value since 2018; 25% of the lost revenues were never recovered.
- Cross-industry, 82% of companies experienced downtime last year. The average outrage lasted for four hours and cost $2 million.
So far, however, the majority of organizations have been relying on manual or outdated statistical anomaly detection techniques. Unfortunately, a lot of them are only partially effective. What’s even more problematic is that the tried-and-tested approaches of today will fully lose their relevance within a few years. Here’s why:
- Big data volumes are growing exponentially: over the last two years, users worldwide generated 90% of global data. Without new tools and automations, human analysts can no longer effectively make sense of it. For instance, it is rather difficult to detect a network anomaly in complex settings, as it’s merely impossible to distinguish “true signals” from the “noise” manually. Manual thresholds can only be scaled up to a certain point. Afterwards, they become ineffective.
- Faster paced business environment: anomalies in databases can leave a business several million dollars short of revenues. Most industries have a strong need for real-time threat analysis and self-service BI to back up their decision-making, minimize downtime and at the same time, improve efficiencies.
- More sophisticated cyberthreats: Fraudulent behavior is getting harder to spot amidst large volumes of data. Cybercriminals are also devising new schemes to exploit existing vulnerabilities and the lack of effective fraud detection mechanisms. Last year’s series of high profile data breaches and hacks are a strong signal, indicating the need for “smarter” prevention and detection of fraud systems.
The more metrics, systems, processes, and environments you need to monitor, the more difficult it becomes to discover data anomalies and deviations manually or using simple automation. Granted, new technological solutions are emerging to augment the capabilities of human analysts – AI-powered anomaly and fraud detection systems.
How to Employ Machine Learning for Anomaly Detection and Intelligent Fraud Detection
The goal of anomaly detection is locating outliers in a given dataset. Outliers are data artifacts that do not come in line with what’s considered “normal” metrics in a dataset. The ‘normal’ parameter, in most cases, is based on some long-standing assumptions, made by comparing the data points to the normal group.
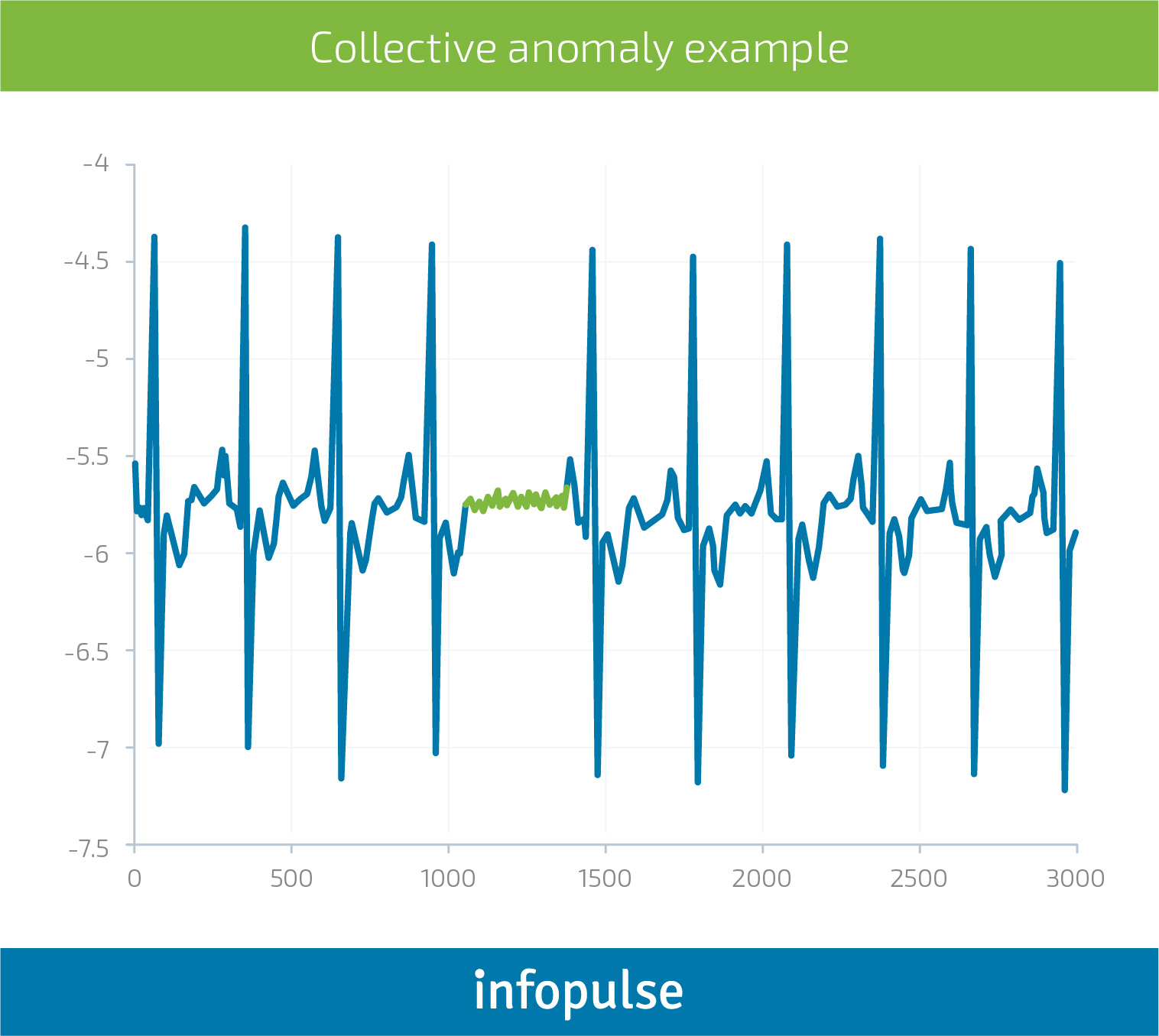
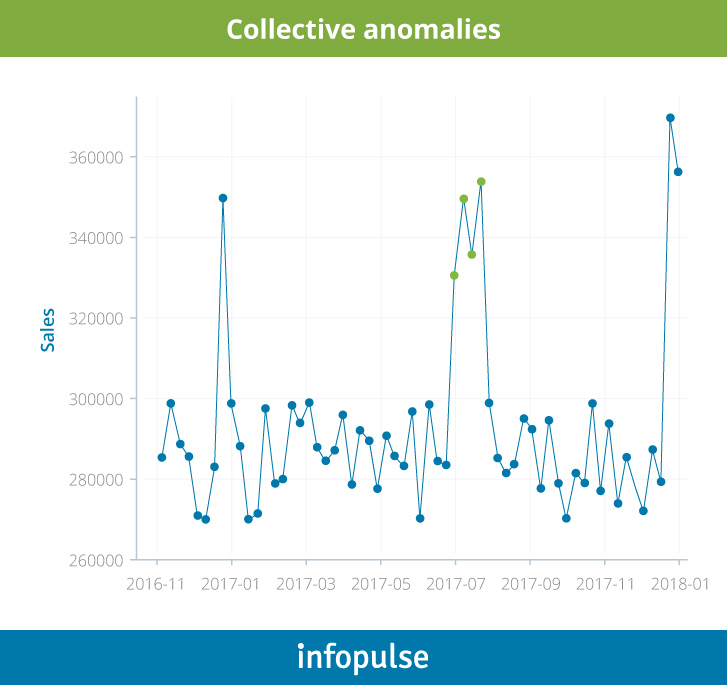
For instance, analysts in charge of detecting fraudulent transactions are usually looking at manual thresholds set for different groups of customers. If they see that customer A has suddenly withdrawn $5,000 from their account three times in a row outside of their typical geolocation (e.g., in Thailand), they may consider investigating the matter.
The problem, however, is that the manual approach often falls short when it comes to complex environments and unexpected patterns in time-series data. Here’s a simple example to illustrate the point:
A global food manufacturer usually needs 10 days to freight raw goods from destination X to Factory B by land. Recently, they switched to another last-mile carrier to expedite the delivery of one type of product, so that they could meet seasonal customer demands. Now, they see some spikes in order delivery time. Are they normal? No. These are noises.
The key to successful analytics and fraud detection is learning how to distinguish abnormal data from noise or seasonality. Machine learning excels in that area.
A high-level explanation of how machine learning-based anomaly detection works is as follows:
- The system processes each data point in sequence, one item at a time. Such an approach allows easy scaling of anomaly detection systems, making them capable of handling large volumes of data. The algorithm is ‘self-learning’, meaning the system understands what ‘business as usual’ is for your organization at any given time.
- To process each data point in the time series, the optimal mathematical model is created to describe that data in the best way possible.
- The algorithm then establishes the value of the next data point.
- If the consequent data point falls outside the normal range, it’s flagged as an anomaly and investigated further.
For a deeper take on the matter, take a look at a 1.30-hour lecture by Tom Dietterich from Microsoft:
In this post, we’ll concentrate specifically on different ML-powered techniques for improving the accuracy of anomaly classifications.
Univariate vs. Multivariate Anomaly Detection Techniques
Univariate outliers (anomalies) are abnormalities present in single feature space (for instance, one business metric). However, not every outlier is an anomaly. Some may be just noise or a by-product of applying clustering algorithms.
Univariate anomaly detection models are relatively simple to build, so it’s easier to scale your system to as many metrics as needed and operationalize large datasets.
If you want to use machine learning to detect fraud, for instance, you’ll also need to understand the causal relationships between the individual metrics and anomalies. That’s the case for multivariate techniques.
Multivariate approaches are aimed at determining “the odd one out” in an n-dimensional space (for instance, a business system that has 10 different data points, characterizing its performance).
The difficulty, in this case, is to accurately determine the relationships between one metric and all the other ones. Such algorithms are backed by complex systems that are harder to scale. They also require computational power and meticulous attention to finer details in data. Alas, that’s a manageable problem if you employ the right method. Here’s a multivariate anomaly detection system developed for an enterprise application by a group of scientists:
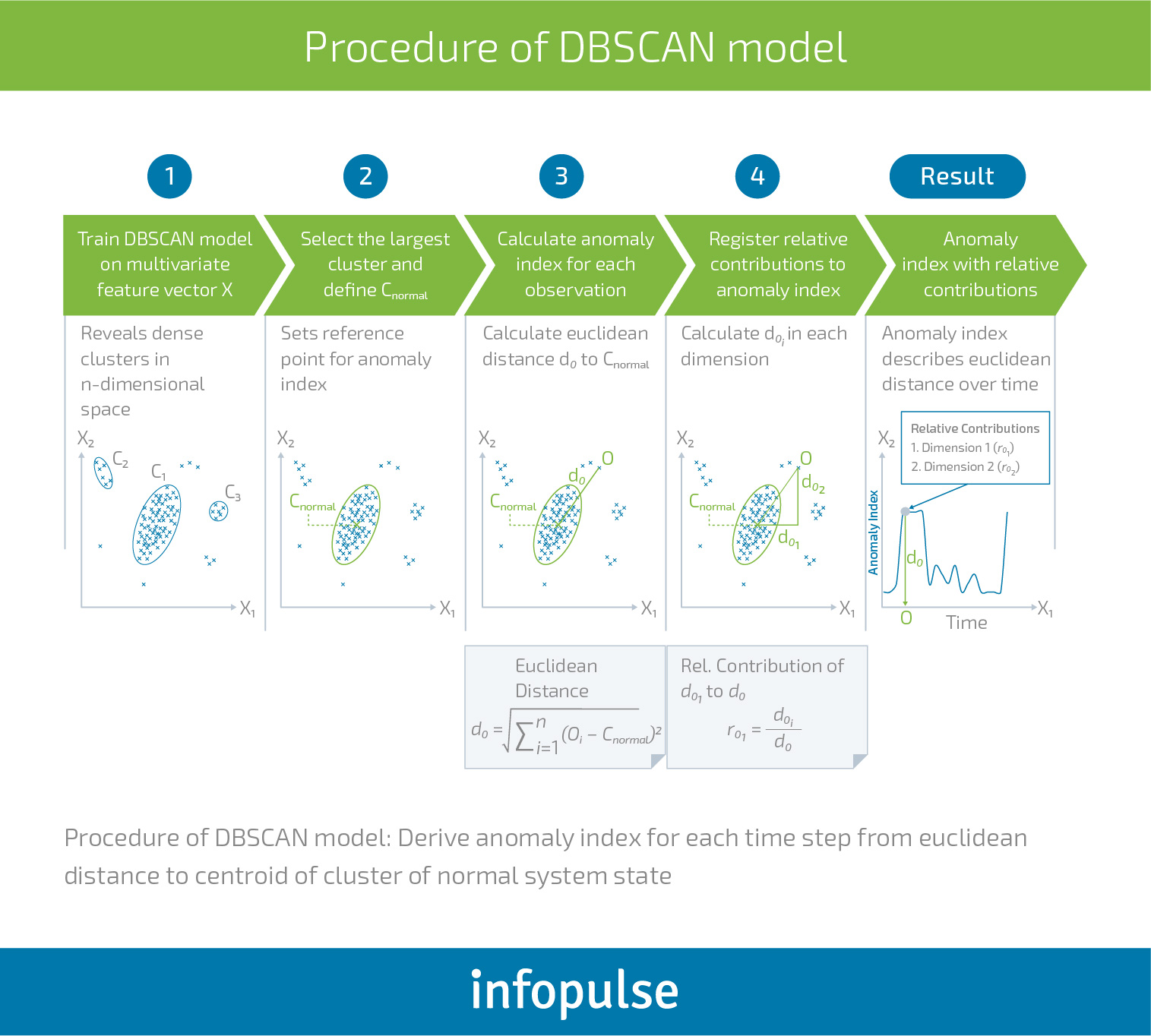
The best methods to use for the multivariate anomaly detection are:
- K-Nearest Neighbors (KNN)
- Cluster-based Local Outlier Factor (CBLOF)
- Isolation Forests
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise) – also used in multivariate analysis.
- Histogram-based Outlier Detection (HBOS)
Both approaches can be employed individually, but the best anomaly detection results usually come from combining the two of them into one hybrid approach.
In hybrid systems, you should first apply univariate anomaly detection methods to individual data points, and afterwards, use more advanced supervised and unsupervised learning algorithms to establish relationships between those data points, and group them into a segment of related anomalies.
For instance, such an AI-powered credit card fraud detection algorithm will be able to group different types of “red flags” – unusual withdrawals, a spike in usage in an unusual location, multiple foreign Internet transactions, etc. – into one final diagnosis – potential credit card theft.
To further understand how AI-powered anomaly detection works, let’s take a look at how machines can be taught to look beyond the root causes and make accurate predictions about unusual events.
Supervised, Unsupervised and Semi-Supervised Anomaly Detection
There are two main categories of learning methods in artificial intelligence:
Supervised learning: In this case, anomaly and fraud detection algorithms are trained by being given an example. That could be a dataset combining both normal and abnormal transaction data types, and the AI is assigned to create a model for distinguishing between them. Afterwards, the system processes uncategorized data and attempts to properly classify each transaction. The shortcoming of supervised learning is that such algorithms can only distinguish fraud patterns that they have been provided within the training dataset. So, such a fraud detection system will need to be provided with a large volume of anomalies, fraud types and others. to be effective.
Unsupervised learning. With the help of deep learning techniques and artificial neural networks, unsupervised AI can be trained to mimic human cognitive patterns. That is learning to draw its own conclusions based on the presented data. Anomaly detection using deep learning means that the system is not explicitly told what’s an outlier. But rather it’s provided with some general rules and characteristics of normal/abnormal data patterns, and then it works its way towards establishing whether a certain data point is an anomaly. Unsupervised systems are harder to train, yet they become more robust in the long run. Due to continuous learning, they become capable of detecting any type of anomaly/fraud, including threats that have never been seen before.
The ‘middle ground’ approach is semi-supervised learning. This learning method assumes the usage of partially labeled data to train the algorithm, with frequent feedback being provided to it in order to increase effectiveness. For instance, a bank wants to use machine learning for fraud detection. They already know about some type of fraud, but are not aware of the newer Internet scams. Thus, the system is presented with a partially labeled dataset. A semi-supervised algorithm can be deployed to label all the data, and then the model can be re-trained using the newly created labeled dataset. Then, the re-trained model can be applied to new data to further increase its effectiveness.
The Business Benefits of Self-Learning ML-based Anomaly Detection Systems
Machine learning can majorly enhance the accuracy, speed, and quality of anomaly and fraud detection in any organization. As abnormal patterns can emerge in any type of data, a variety of industries can gain a major edge by switching to AI-powered anomaly detection.
Supply Chain Management: Supply chain inefficiencies are rampant and can cause major disturbances in the entire ecosystem (the bullwhip effect), as well as result in wasted productivity and revenue. ML-powered anomaly detection can be applied towards demand planning and provide a better forecast than traditional analytics 75% of the time. Furthermore, such systems can improve inventory management, automate root cause analysis, enhance supply and production planning.
Telecommunications: Leading Telcos are actively exploring network anomaly detection use cases, aimed at improving infrastructure health and gaining more insights into the operations. Turkcell is also using ML-powered telecom fraud detection techniques to achieve near real-time feedback on abnormal behaviors, identify suspicious charges, phishing calls and even fraudulent sales patterns across their organization.
Healthcare: Medical fraud detection is another hot area for employing supervised and unsupervised AI. Intelligence algorithms are being used to find fraud and abuse in medical payments, and gradually become the backbone of some newer insurance fraud detection techniques applied by medical institutions. Also, AI can majorly enhance the diagnosis procedures, with unsupervised anomaly detection being used in X-Ray image analysis. Lastly, with the rising demand for medical IoT devices and health wearables, real-time anomaly detection will become crucial as it can help notice the early signs of an upcoming crisis and alert the patient and medical staff.
To conclude, real-time AI-powered anomaly detection can help your company get a more wholesome, holistic view of the information hidden within your data lakes. Machine learning algorithms can effectively work across systems and supply a deeper level of insight about a variety of processes and hidden problems.
Learn more about Inflopulse excellence in deploying cutting-edge BI, Big data and predictive analytics solutions for anomaly and fraud detection by getting in touch with our specialist!
![Pros and Cons of CEA [thumbnail]](/uploads/media/thumbnail-280x222-industrial-scale-of-controlled-agriEnvironment.webp)

![Power Platform for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-power-platform-for-manufacturing-companies-key-use-cases.webp)
![Agriculture Robotics Trends [Thumbnail]](/uploads/media/thumbnail-280x222-what-agricultural-robotics-trends-you-should-be-adopting-and-why.webp)
![ServiceNow & Generative AI [thumbnail]](/uploads/media/thumbnail-280x222-servicenow-and-ai.webp)

![Data Analytics and AI Use Cases in Finance [Thumbnail]](/uploads/media/thumbnail-280x222-combining-data-analytics-and-ai-in-finance-benefits-and-use-cases.webp)
![AI in Telecom [Thumbnail]](/uploads/media/thumbnail-280x222-ai-in-telecom-network-optimization.webp)

