
5 Pitfalls of Implementing Computer Vision and How to Avoid Them
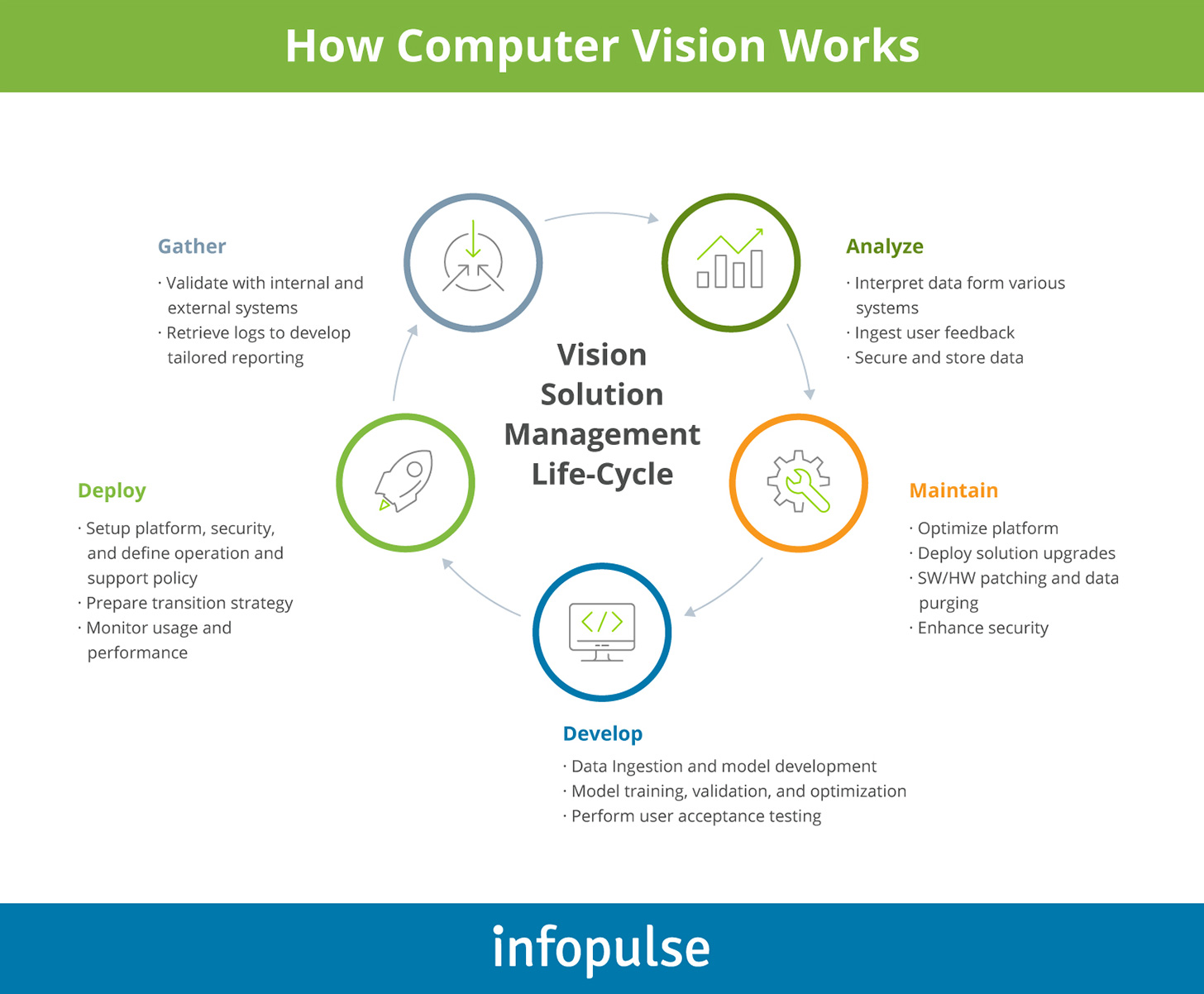
By 2027, the global computer vision market size is projected to reach $19.1 billion. Much of the growth will be fueled by the wider adoption of artificial intelligence solutions for quality control in manufacturing, facial recognition, and biometric scanning systems for the security industries, and the somewhat delayed, yet still imminent arrival of autonomous vehicles. The rapid progress in deep learning algorithms (and Convolutional Neural Network (CNN) in particular) accelerated the scale and speed of implementing computer vision solutions.
However, despite an overall positive outlook, there is still a cohort of factors constraining computer vision implementations. We lined up the top-5.
1. Suboptimal Hardware Implementation
Computer vision applications are a double-pronged setup, featuring both software algorithms and hardware systems (cameras and often IoT sensors). Failure to properly configure the latter leaves you with significant blind spots.
Hence, you need to first ensure that you have a camera, capable of capturing high-definition video streams at the required rate per second. Then you need to ensure a proper angle for capturing the object’s position. When you test the setup, make sure that the cameras:
- Cover all areas of surveillance.
- Are properly positioned. The frame captures the object from the correct angle.
- All the necessary configurations are incheck.
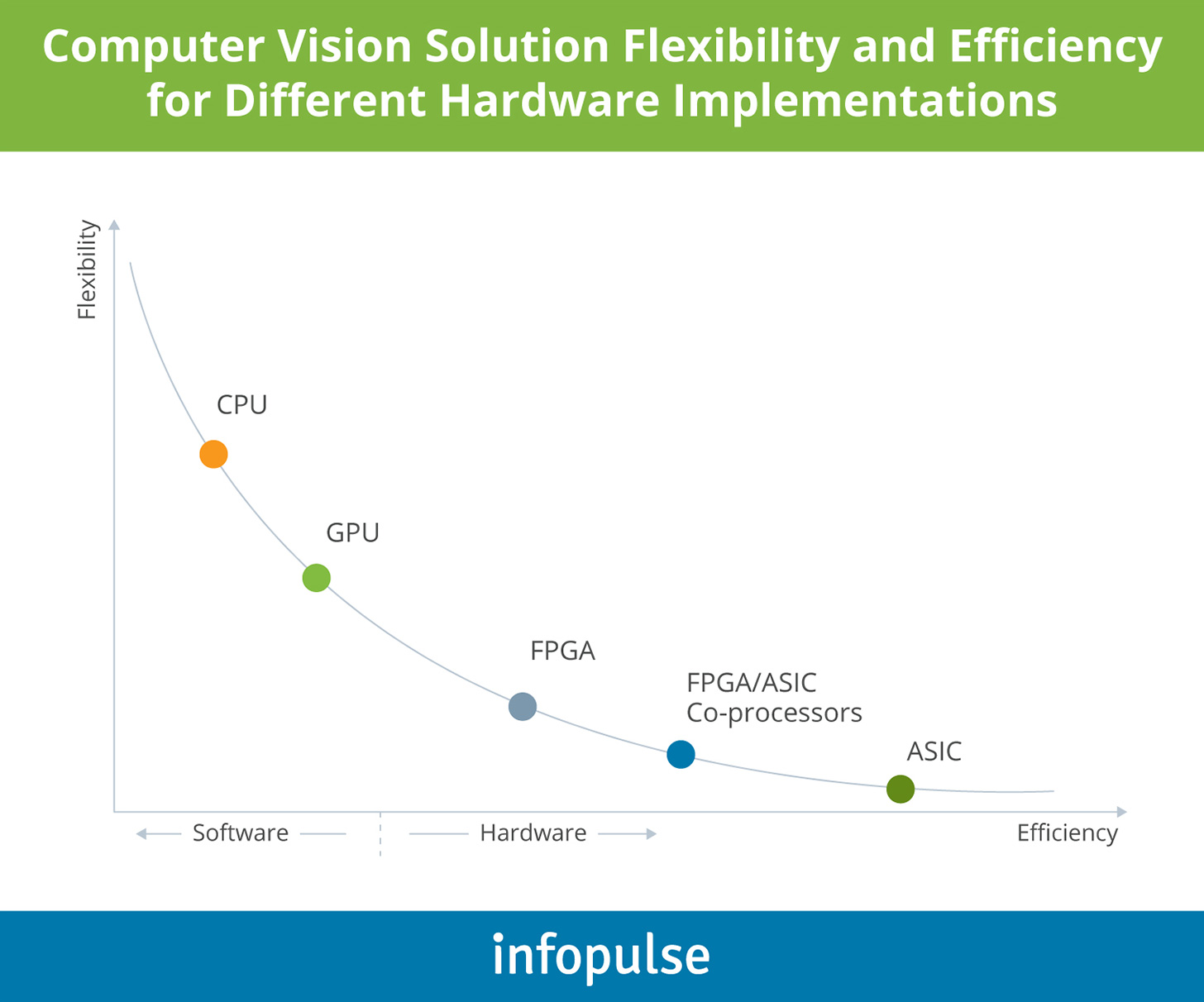
Apart from cameras, you will also need to ensure proper hardware acceleration for computer vision software. Machine learning and deep learning algorithms are computationally demanding and require optimized memory architecture for faster memory access. Respectively, stack up on CPUs and GPUs.
CPUs, in particular, are the best fit for computer vision tasks (especially those involving deep learning and neural networks) as they support effective serial computations with complex task scheduling. The chart below compares the efficacy rates of different hardware acceleration solutions for computer vision:
2. Underestimating the Volume and Costs of Required Computing Resources
The boom in popularity of AI technologies (ML, DL, NLP, and computer vision among others) have largely commoditized access to best-in-class computer vision libraries and deep learning frameworks, distributed as open-source solutions.
For skilled data scientists, coming up with an algorithmic solution to computer vision problems is no longer an issue (even if we are talking about advanced computer vision scenarios such as autonomous driving). The modeling know-how is already available. It is computing power that often constrains model scaling and large-scale deployments.
We noticed that when going forward with computer vision technology, many business leaders underestimate:
- Project hardware needs
- Cloud computing costs
As a result, some invest in advanced algorithm development, but subsequently, fail to properly train and test the models because the available hardware doesn’t meet the project technical requirements.
To better understand the costs of launching complex machine learning projects, let us take a look at the current state-of-the-art image recognition algorithm. A semi-supervised learning approach Noisy Student (developed by Google) relies on convolutional neural networks (CNN) architecture and over 480M parameters for processing images. Understandably, such operations require immense computing power.
Researchers from AI21 Labs estimated the average cost of training similar deep learning networks in the cloud (using AWS, or Azure or GCP):
- With 110 million parameters: $2.5k – $50k
- With 340 million parameters: $10k – $200k
- With 1.5 billion parameters: $80k – $1.6m
Please be aware that the above only accounts for model training costs (without retraining), but the ballpark estimates include the costs of performing hyper-parameter tuning and doing multiple runs per set.
The best computer vision software is power-hungry. Hence, make sure that you factor in all the computing costs, invest in proper hardware, and proactively optimize the costs of cloud computing resources, allocated to computer vision.
3. Short Project Timelines
When estimating the time-to-market for computer vision applications, some leaders overly focus on the model development timelines and forget to factor in the extra time needed for:
- Camera setup, configuration, and calibration
- Data collection, cleansing, and validation
- Model training, testing, and deployment
Combined, these factors can significantly shift project timelines. How can you make more accurate estimates?
A 2019 study by Algorithmia brought some sobering insights:
- In 2019, 22% of enterprises successfully productized their AI models.
- Among this cohort, 22% needed one to three months to bring one ML model into production (given that they have a mature MLOps process).
- Another 18% required three or more months for deployments.
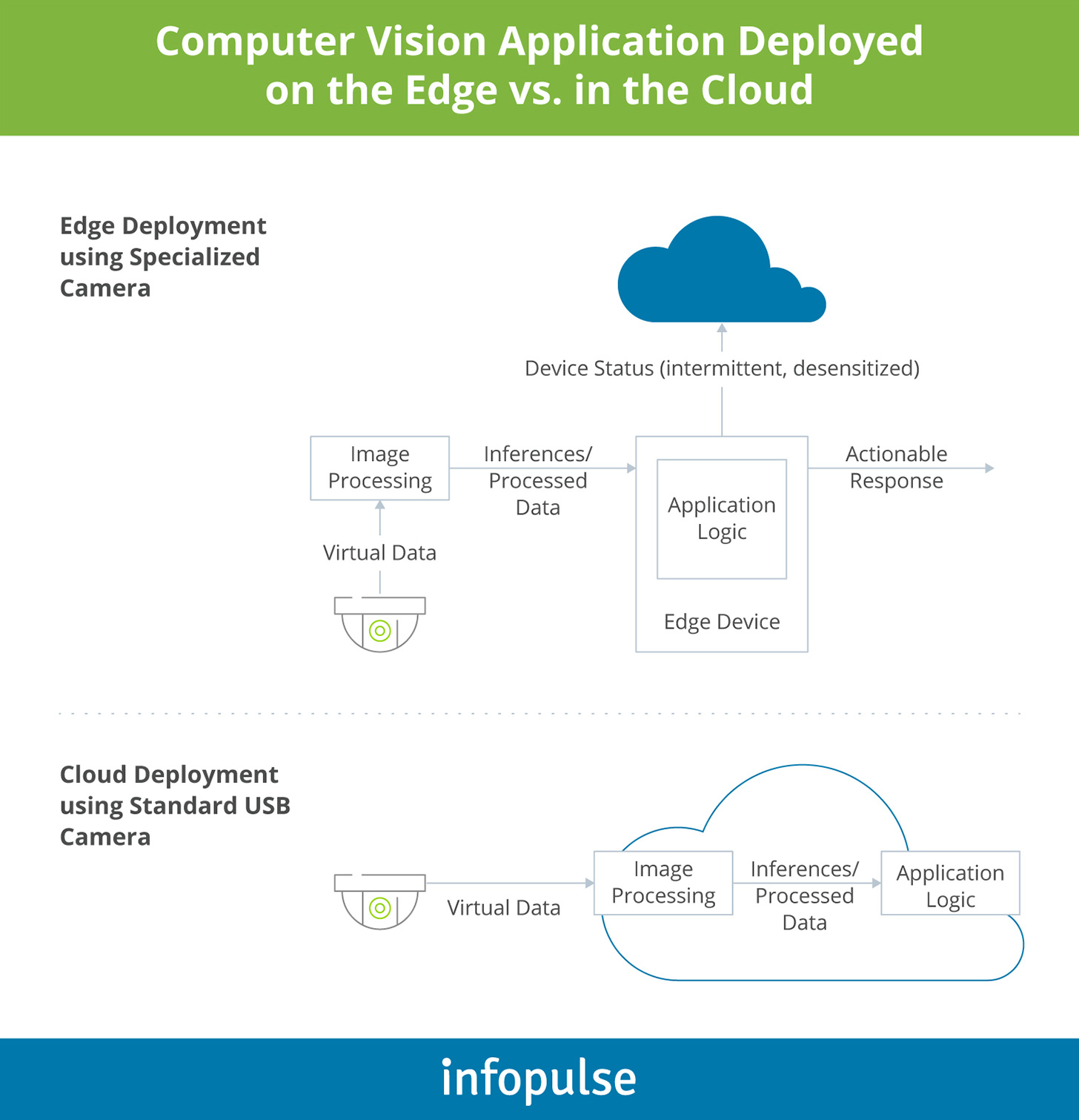
The deployment stage of computer vision technologies, especially the complex systems running in hybrid cloud environments, requires careful planning and preparation. In particular, consider the pros and cons of different target deployment environments such as:
- Cloud platforms: Deploying computer vision algorithms to the cloud makes sense if you need the ability to rapidly scale the model performance, maximize uptime, and maintain close proximity to the data lakes the model relies on. On the other hand, the cloud may not always be suitable for processing sensitive data. Plus, the computing costs can rise sharply without constant optimization.
- Local hardware: It is possible to run computer vision solutions on-premises too. The option works best for businesses with idle server resources who would like to re-deploy them for testing pilot deployments and small-scale projects. The con, however, is expensive and/or constricted scalability.
- Edge: Running computer vision models on the edge devices, connected or embedded into the main product (e.g., the camera system, manufacturing equipment, or drone) can significantly reduce latency for transferring high-definition visuals (video in particular). However, edge deployments also require more complex system architecture and advanced cybersecurity measures in place to protect data transfers. One of the solutions to these issues is to use peripheral cameras that do not have internet connectivity but can be meshed with edge devices to expand the application functionality.
4. Lack of Quality Data
Labeled and annotated datasets are the cornerstone to successful CV model training and deployment. General-purpose public datasets for computer vision are relatively easy to come by. However, companies in some industries (for example, healthcare) often struggle to obtain high-quality visuals for privacy reasons (for example, CT scans or X-ray images). Other times, real-life video and images are hard to come by (for example, footage from road accidents and collisions) in sufficient quantity.
Another common constraint is the lack of a mature data management process within organizations which makes it hard to obtain proprietary data from siloed systems to enhance the public datasets and collect extra data for re-training.
In essence, businesses face two main issues when it comes to data quality for computer vision projects:
- Insufficient public and proprietary data available for training and re-training
- The obtainable data is of poor quality and/or requires further costly manipulations (e.g., annotation).
The better news is that you can improve your datasets programmatically to enhance the model performance:

Synthetic data is another novel approach to improving data quality for computer vision projects. Synthetic datasets are programmatically generated visuals that can be used for more effective model training and retraining as the chart below illustrates:
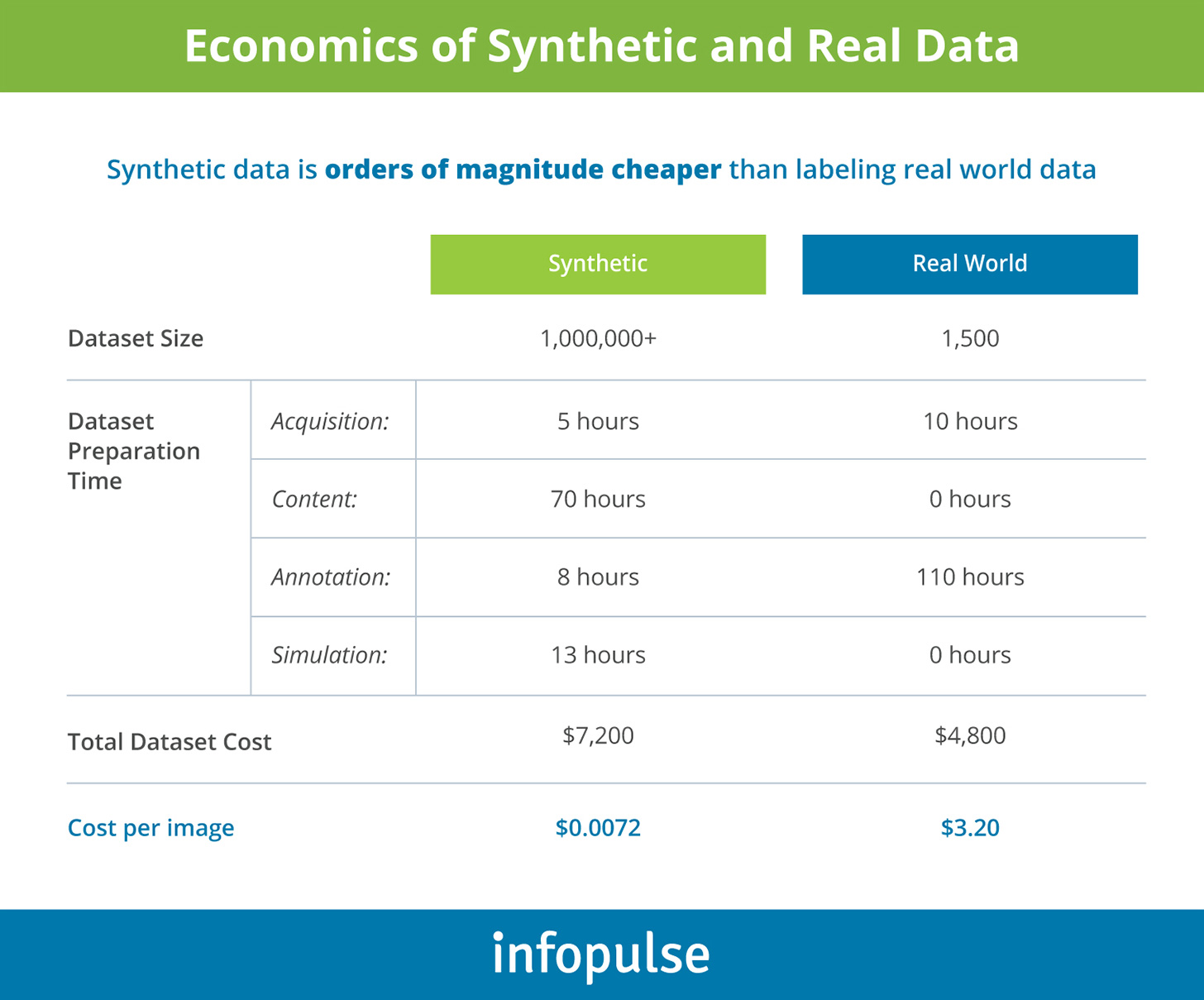
Synthetic data is more affordable to produce, but how does its usage affect model accuracy? Several use cases illustrate that models trained on mixed datasets (featuring both real-world and synthetic data) often perform better than those using real-world data only.
- A robot arm trained for grabbing accuracy using synthetic data only can achieve accurate performance results with real-life objects.
- Google’s Waymo is said to be validated and cross-trained with synthetic data.
- Another subdivision at Google trained a computer vision model for detecting items on the supermarket shelves using synthetic data. The algorithm did better than one trained on real-life data.
5. Inadequate Model Architecture Selection
Let us be honest: most companies cannot produce sufficient training data and/or don’t have high MLOps maturity for churning out advanced computer vision models, performing in line with the state of the art benchmarks. Respectively, when it comes to project requirements gathering, the line of business leaders often set overly ambitious targets for the data science teams without assessing the feasibility of reaching such targets.
As a result, when it comes down to the later development stages, some leaders may realize that the developed model:
- Does not meet the stated business objectives (due to earlier overlooked requirements in terms of hardware, data quality/volume, computing resources)
- Demands too much computing power, which makes scalability cost-inhibitive.
- Delivers insufficient results in terms of accuracy/performance and cannot be used in business settings.
- Relies on a custom architecture that is too complex (and expensive) to maintain or scale in production.
To avoid such scenarios, dwell more on building a solid business case for your project. Analyze your current technical maturity levels and the ability to collect proprietary data or purchase labeled datasets or synthetic data. Factor in the model development, training, and deployment costs. Then examine feasible computer vision use cases and winning case studies from other players in your industry.
Here are several successful computer vision case studies from the Infopulse team:
- AI-powered mask-wearing detector for public spaces
- Integrated smart camera solution for an automotive client
- Image recognition solution for the manufacturing industry
To Conclude
Investment in computer vision has picked up speed across industries. From the manufacturing industry to the retail sector, leaders are seeking out ways to improve their ability to detect objects, capture information from images, and gauge the object’s positioning and movements. Further acceleration of computer vision research can unlock a host of new revenue streams for businesses — from unattended, unmanned commerce to automated irrigation and harvesting of fields.
At the same time, computer vision use cases are complex and require both expertise and deeper technological transformations for many players. To obtain quantifiable ROI, you need to build a strong business case for automation, account for a wide spectrum of implementation costs, and verify the scalability of the selected CV architecture.
Contact Infopulse computer vision specialists to help you shape your vision for a new computer vision solution and provide a preliminary overview of the implementation feasibility, constraints, and costs.
![Pros and Cons of CEA [thumbnail]](/uploads/media/thumbnail-280x222-industrial-scale-of-controlled-agriEnvironment.webp)

![Power Platform for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-power-platform-for-manufacturing-companies-key-use-cases.webp)
![Agriculture Robotics Trends [Thumbnail]](/uploads/media/thumbnail-280x222-what-agricultural-robotics-trends-you-should-be-adopting-and-why.webp)
![ServiceNow & Generative AI [thumbnail]](/uploads/media/thumbnail-280x222-servicenow-and-ai.webp)

![Data Analytics and AI Use Cases in Finance [Thumbnail]](/uploads/media/thumbnail-280x222-combining-data-analytics-and-ai-in-finance-benefits-and-use-cases.webp)
![AI in Telecom [Thumbnail]](/uploads/media/thumbnail-280x222-ai-in-telecom-network-optimization.webp)

