
How Can Big Data Help My Business Earn More?
Source: AIN.UA
What is it all about?
We had a separate article on Data Science and what it is, which also included the information on big data and how it works. In brief, big data is an enormous data bulk which allows data mining if properly processed, and using the discovered insights to improve efficiency.
The information received by the company after the data is ‘run’ through the analysis algorithm, is valuable as a big data product. It should be verified by the analyst or a specialist in the appropriate field of human activity (e.g., medicine); it can be used further to change processes inside the company or to gain more profit or to minimize costs among other things.
How does it work?
When we talk about ‘big data’, we mean a statistics processing method rather than the statistics bulk (e.g., radish and perfumes are better sold in N shop during the lunch break every third day of the month). Traditional technologies can also ‘digest’ big data, but the more information we have, the more slowly they cope with it. Traditional algorithms efficiency is massively lower with the same expenses. For instance, if the amount of data doubles, data processing rate falls four times.
One of the standard big data processing approaches implies two things: process paralleling and use of a distributed file storage. It allows keeping linear relations between the information amount and its processing rate. For instance, if the amount of information in the database doubles, it is necessary to double the number of servers connected to it in order to keep the same processing rate.
Professionals working with big data like using the following diagram to visualize how big data processing algorithm MapReduce works.
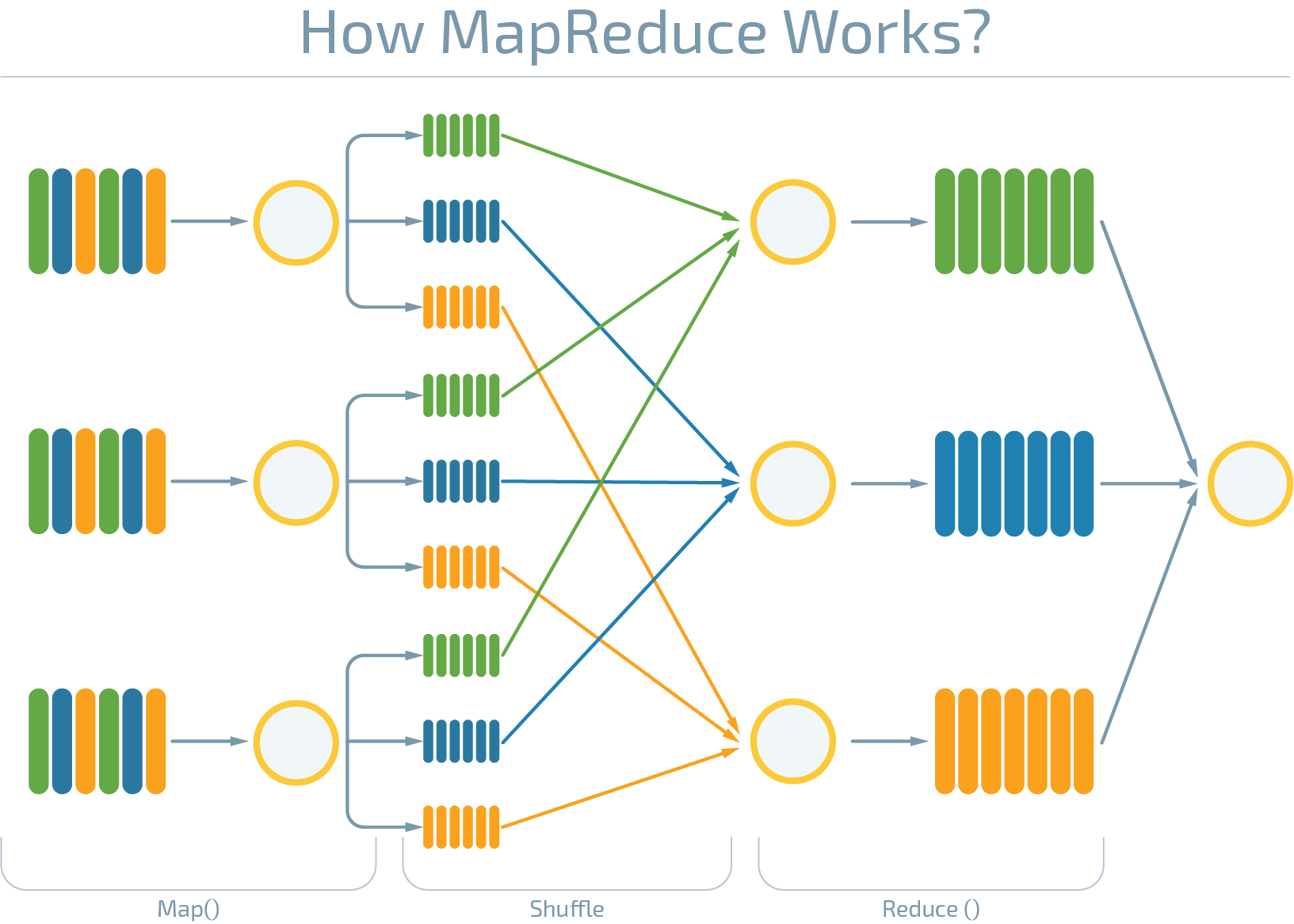
MapReduce algorithm consists of two functions: Map and Reduce. Map function splits all the incoming data into small units that can be analyzed independently of one another. When the data is split, Reduce function is launched that analyzes each independent bit of data and then brings them all together. So, insights are discovered in the data in such a way.
How can such data be useful?
There are enough cases in the world which demonstrate how big data allows working more effectively.
For instance, Microsoft and Siemens developed a ‘smart’ X-ray machine. It takes a picture with the help of X-rays and sends it for analysis to the healthcare professional and to the cloud simultaneously. The cloud contains a picture analysis system based on artificial intelligence that processes the received picture constantly learning (machine learning). The doctor and the system make a diagnosis; if there are big discrepancies, the doctor receives a notification that it is necessary to revise the diagnosis. It so happens from time to time that the system makes a wrong decision, but it also often helps see hidden things that the human hasn’t noticed.
Big data processing algorithms have been used in a recent investigation of British authorities regarding corruption in Roll-Royce. ACE robot of a British startup Ravn helped investigators analyze 30 million documents, which considerably accelerated the process and decreased the costs of routine human labor. A man in flesh and blood is unlikely to analyze 600,000 documents a day with minimum error.
Kodisoft uses big data processing technologies in their interactive tables learning their clients’ preferences in such a way and making a more accurate recommendation for them.
Or, for example, AgroMonitor, one of Ukrainian agricultural startups, analyzes based on findings from fields how to get an optimal result calculating expenses on fields tillage. For instance, if after planting a hundred sacks of potatoes one reaps a harvest of two hundred sacks, or after planting two hundred sacks, one gets three hundred, what is more profitable for a farmer in absolute terms after all?
Forland, one more agricultural startup from Ukraine, collects all the statistics in its software on field work: what crops are grown, how many machines and material values are involved, what the weather is like during such campaign. First, big database allows any agriculturalist who received the field statistics start working with a good basis rather than from scratch; second, it allows discovering insights while collecting new data.
Among retailers and in distribution, big data allows finding out interconnections between the demand for certain groups of goods and the weather or events nearby and therefore allows renewing supplies more effectively. At least one more Ukrainian company is working on such a product.
Each business or line of work have their own profit from big data. The key aspect is that Big Data allows acting purposefully and releasing human resources for more creative and complicated activities. For instance, the analyst who explores business indicators doesn’t have to do routine work: manual calculation thanks to the implementation of machine processing algorithms; they may take advantage of ready-made results calculated by machines. Machine algorithms may be used as a tool for redundancy by professionals whose work requires enhanced alertness (healthcare professionals, lawyers) and they may draw their attention to the cases that stand out from the total body of results.
I want to earn more with Big Data too! Where do we start?
With the right goal setting and data collection.
“To earn by means of big data” is not a goal. The goal can lie in optimizing a certain expenditure item, in raising income, in pushing up sales, depending on your company’s activities and its sore points.
Even if you can’t define the goal, it makes sense to collect data anyway. As when the goal is clear, algorithms will require information for analysis in any case, and there should be as much information as possible. Besides, the place where the date is kept is currently one of the smallest expenditure items unlike the data analysis systems. For example, Azure has recently decreased the prices to several cents per Gigabyte, that is why information collection won’t hit you in the wallet.
What comes next? Who should deal with it?
Ideally, there should be two people in the company dealing with data gathering and analysis (there may be even one, but there are virtually two tasks). On the one hand, it is the analyst who will build a machine learning model or at least write on paper what data should be analyzed and how. On the other hand, it is an engineer who knows how to develop data. Next, one of the modern-day platforms to operate big data can be of help. Microsoft, SAP, Google, Amazon, Oracle, and IBM have their own solutions.
OK, what platform to choose?
One and the same solutions to work with big data can technically be implemented on all current platforms. The choice depends on how flexible the system you need should be and how many resources you are ready to spend on its customization and support. For instance, Microsoft allows choosing a pre-configured solution which is less flexible or tools to personalize the system independently. Other systems offer the second variant of interaction. The difference between approaches can be seen using pizza as an example.
If you would like to cook pizza, you can do it in two ways: buy all the ingredients, mix the dough and make a pizza crust and a topping or buy a half-prepared product and be busy only with a topping. In the first case, you will have the ultimate freedom of choice as to the size, shape, etc., but all the responsibility for the result will fall on your shoulders and the production time will increase correspondingly. If you have a good experience in fully integrated production, you will most likely succeed, or not, but if you don’t succeed, you will have to come to grips with problems independently.
If you decide to work with a half-prepared product, in fact, you will be able to cope only with a topping, but you will get rid of pain in the neck regarding the remaining process; if the pizza crust does not correspond to the announced profile, you won’t have to correct it.
Broadly speaking, the use of pre-configured solutions reduces the starting time of the product to several minutes, delivering from the necessity of keeping the system operational. Configuration by own efforts requires a higher qualification, more time for system start and more technical support expenses, but it gives you free hand concerning the way the system operates.
Consequently, the choice should be done through the lens of effort used to start working with big data.
If you want to learn more about Big Data and understand how to create such a solution for your business, feel free to contact us today.
![Pros and Cons of CEA [thumbnail]](/uploads/media/thumbnail-280x222-industrial-scale-of-controlled-agriEnvironment.webp)

![Data Analytics and AI Use Cases in Finance [Thumbnail]](/uploads/media/thumbnail-280x222-combining-data-analytics-and-ai-in-finance-benefits-and-use-cases.webp)
![Data Analytics Use Cases in Banking [thumbnail]](/uploads/media/thumbnail-280x222-data-platform-for-banking.webp)
![Digital Twins and AI in Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-digital-twins-and-ai-in-manufacturing-benefits-and-opportunities.webp)


![Big Data Use Cases in Agriculture [thumbnail]](/uploads/media/thumbnail-280x222-key-agro-challenges-solved-by-advanced-data-analytics.webp)

![Manufacturing Trends 2024 [Thumbnail]](/uploads/media/thumbnail-280x222-manufacturing-trends-that-will-shake-the-world-in-2024.webp)