
The Executive Guide to Neural Networks and Deep Learning for Businesses
The progress has been rapid, impacting every industry on the planet – from the most traditional ones like agriculture to the emerging disciplines like robotics. The vast majority of this rapid progress can be attributed to advances in deep learning – the novel approach to creating the most “human-like” artificial intelligence.
What is Deep Learning (DL)?
Deep learning is a subdivision of machine learning with a strong emphasis on teaching computers to learn like humans: by being presented with an example.
As a child, you easily learn how an apple looks – the shape, the color, the texture – and you learn to understand that when you hear the word “apple”, you will likely receive a sweet, round red object that you can bite into.
Deep learning methodologies operate on the premises that machines can be taught from experience as well. The algorithm is presented with the same task repeatedly, and each time receives feedback on its performance so it could adjust its accuracy in the future.
How Deep Learning is Different from Machine Learning
Deep learning is a subdivision of machine learning. Both disciplines pursue the same goal – teach machines to become “smarter” in what they do.
Machine learning algorithms can be programmed to perform accurate tasks – classify data, predict prices and so on. As new data becomes available, their performance improves. However, those improvements and adjustments need to be performed by a human engineer.
Deep learning reduces the level of human involvement in the teaching process. Such algorithms are only given data and the initial parameters for operationalizing that data. They are capable to determine whether their output (prediction or action) is accurate or not on their own.
Let’s illustrate this with a quick example. You have a voice-controlled thermostat, programmed to adjust the temperature whenever you activate it and say “20℃”. If it’s powered by machine learning, over time it can learn to capture the digit component in more complex commands – e.g., “Please, make it 20℃ at home”.
Now, if your thermostat is powered by a deep learning model, over time it could figure out to start adjusting the temperature whenever it hears something like “Gosh, it’s cold!” or “I’m freezing today!”. In essence, it’s capable to learn using its own “brain” or more precisely – an artificial neural network.
What is a Neural Network?
Deep learning and neural networks are the pillars for building the new generation of intelligent solutions.
Artificial neural networks
Artificial neural networks are algorithmic representations of biological neural networks, which are powering different cognitive processes inside the human brain – vision, hearing, decision-making. Artificial networks can learn from a large volume of data, by example with little-to-no supervision.
There’s not much of a difference between deep learning and neural networks, as the latter is the baseline method of DL. Deep learning assumes using a subset of neural networks to accomplish various tasks. The term “deep” was added exactly due to the fact that artificial neural networks come with a varying number of (deep) layers, powering the learning process.
So, how do neural networks work? In short, each ANN consists of “artificial neurons” – mathematical functions that analyze incoming data and transmit it to the next “neuron” for further analysis. Every layer in the network focuses on analyzing specific features, e.g., shadows in edges in number 1 for written digit recognition tasks, before passing on the “knowledge” to another layer that will perform further operations with it before delivering the result, e.g., recognizing number 1 as one.
To further understand how neural networks function, let’s take a closer look at the common types of neural networks developed up to date.
Feed forward neural networks
Feed forward neural networks are the most “simple” type of an artificial neural network, first proposed in 1958 by AI pioneer Frank Rosenblatt. Within such network, information travels only one-way – from left to right, through the input nodes, then through the hidden nodes (if any) and afterwards through the output nodes.
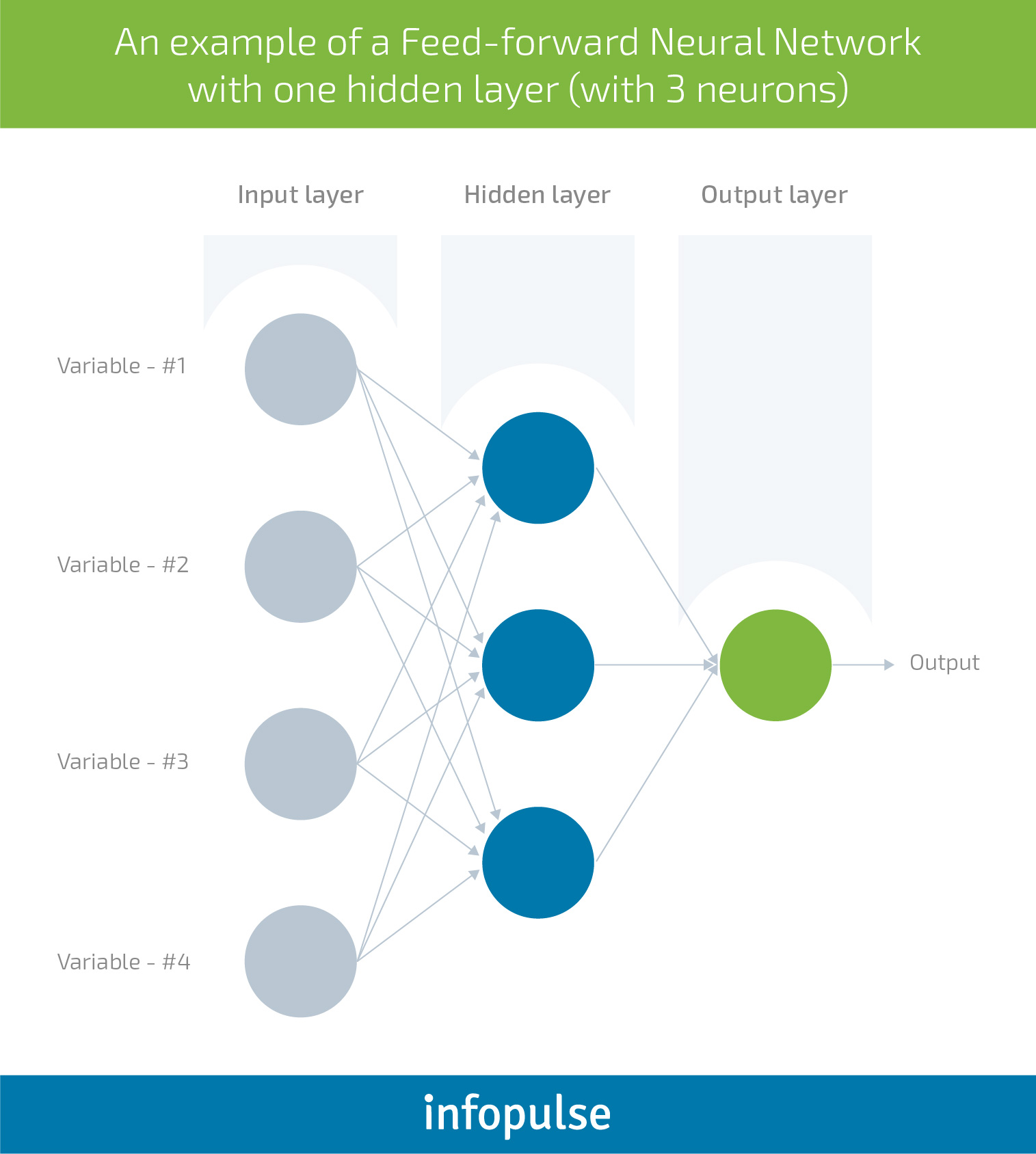
Each node in the layer is an artificial neuron – represented by a function that performs required calculations for the task at hand, e.g., classify the data based on a certain parameter. To move from the Input layer (when data or features are provided to the network) to Output layer (which delivers the prediction) – different linear or nonlinear functions are applied.
Hidden layers enable the computation of more complex functions by cascading simpler functions. In other words, a network with no hidden layer (a simple artificial neuron) is only capable of learning a linear decision boundary, i.e., classify all the blue dots to one side of the decision boundary and all the red ones to the other side, but it will not be able to handle more complex decisions.
Thus, hidden layers enable additional learning capabilities that can tackle more complex decisions. Neural networks further vary depending on the type of hidden layers used.
Recurrent neural networks (RNNs)
In this case, the input information travels through a loop. Before producing a decision, the network will take into consideration the current input, plus the data it has captured from the previously operationalized inputs.
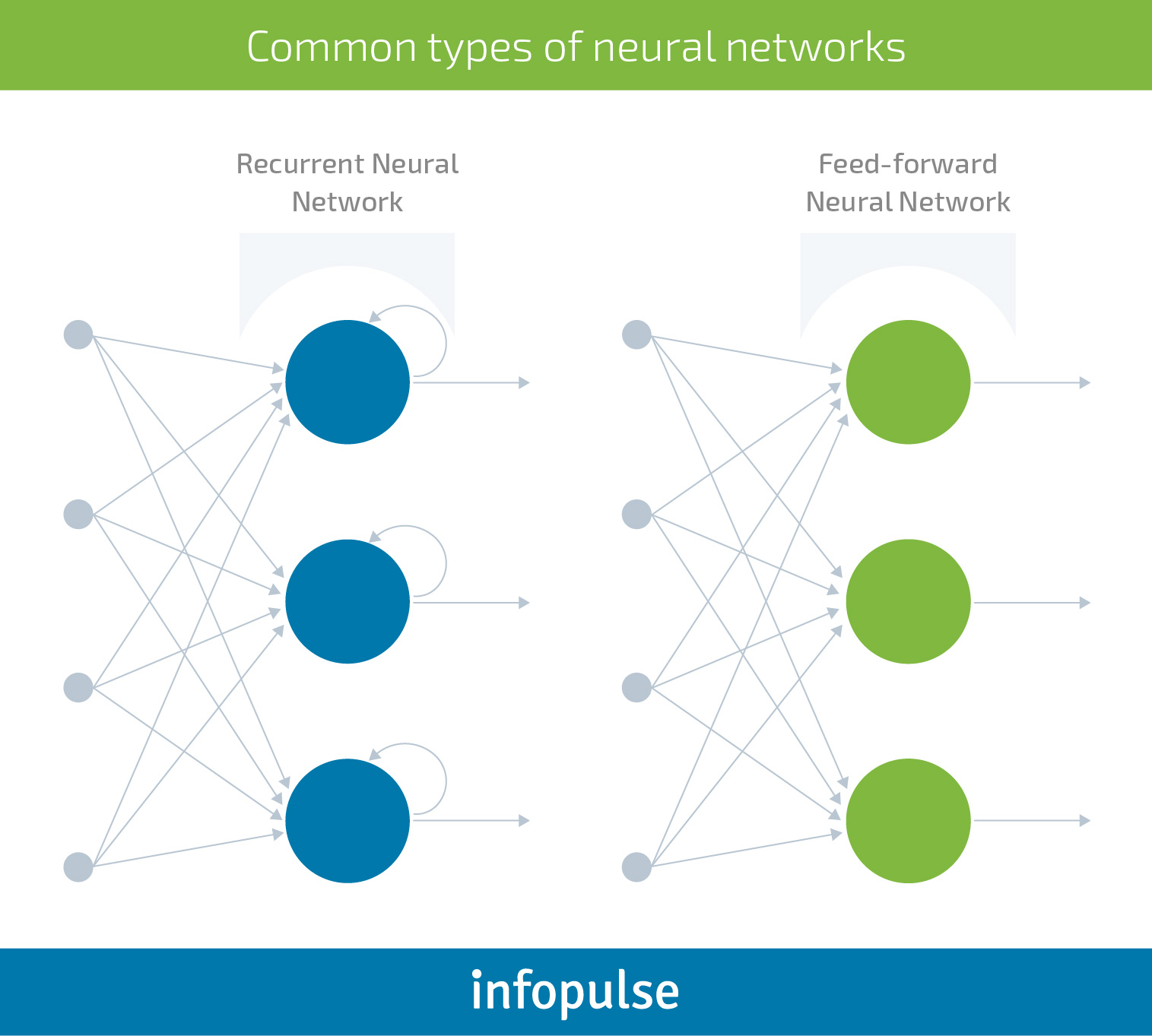
RNNs come with a short-term memory. They are aware of the recent past as it produces a certain output, “remembers it” and loops it back into the network. This memory feature makes RNNs highly effective for tasks such as speech and text recognition; financial data analysis and predictions; and more. Unlike other algorithms, they have a deeper understanding of a sequence and its context. This way they produce predictive results in sequential data that no other algorithm can muster.
Convolutional neural networks (CNNs)
Convolutional neural networks are the closest technical similitude to the brain we have managed to develop so far. These deep artificial networks attempt to closely mimic the processes running in our primary visual cortex, responsible for our ability to “see” and “recognize” objects. Thus, CNNs are mainly used for image/video recognition tasks.
CNNs differ from the other two types of networks. The layers are organized in 3 dimensions: width, height and depth. This structure enables better recognition of different objects.
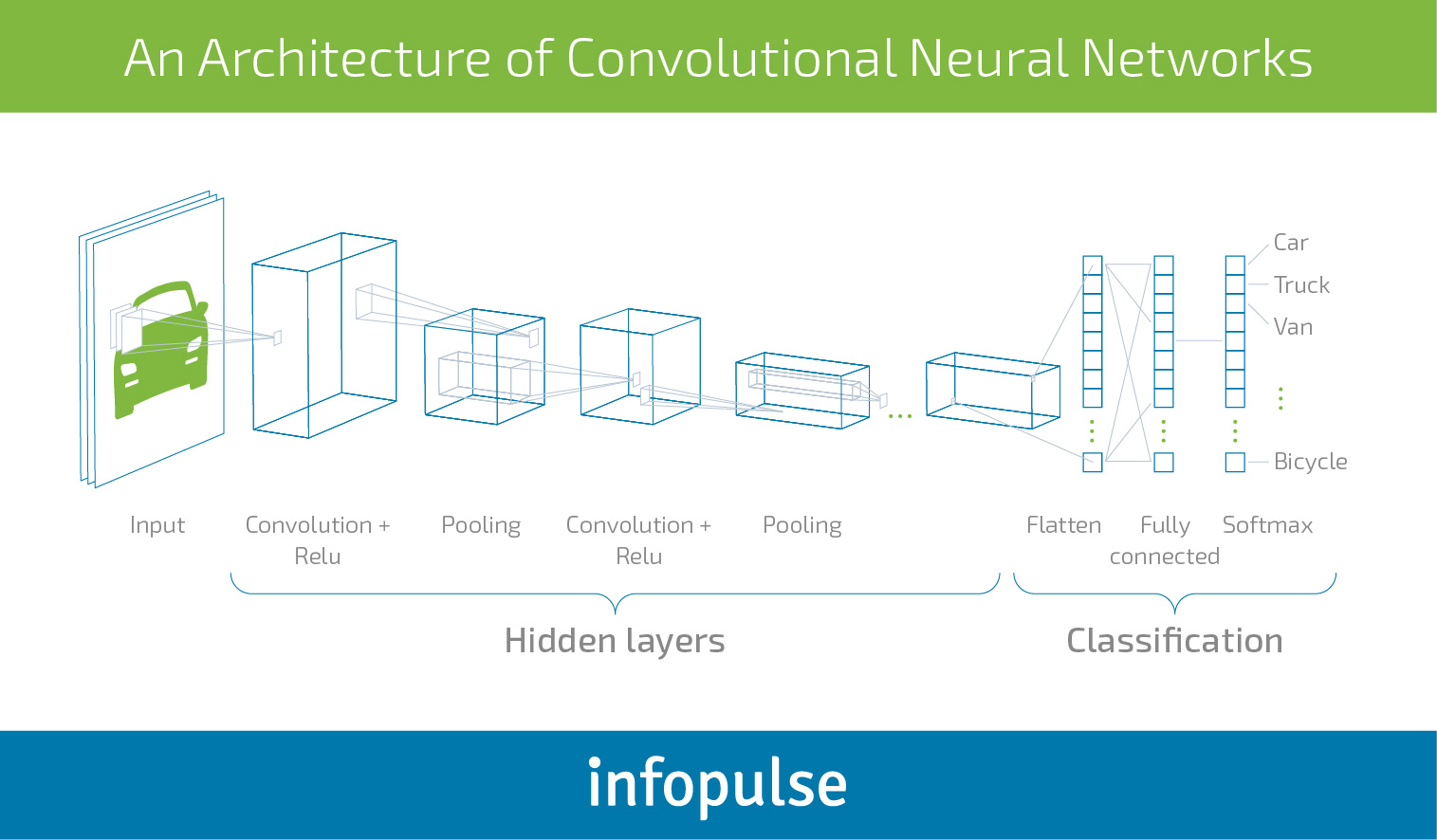
As you can see above, this example of neural network has two distinctive components:
- Hidden Layers – at this stage, the network performs a series of operations trying to extract and detect specific image features. If you have a picture of a car, the network will learn how a wheel, a door, a window looks like.
- Classification – additional layers serve as a classifier on top of the extracted features. These layers will determine the probability of how likely the image is being what the algorithm predicts it is.
So, what are neural networks capable of in the business setting apart from classifying data and recognizing patterns?
- Continuous estimation: NNs are the perfect candidates for dealing with time series data prediction. For example, by being given historic sales figures, current market trends, weather and consumer sentiment, a network can estimate the demand for winter boots or another seasonal product or service.
- Clustering: create different customer segments based on demographic data, online behavior, and preference data from individual consumers.
- Process optimization: estimate the best route for a fleet based on different parameters such as time and fuel usage.
- Advanced recommendations: suggest the “song you will like” or “product to buy” with an accuracy higher than traditional predictive analytics algorithms.
- Anomaly detection: a network could be trained to recognize different trading patterns and estimate when a spike or a crash is most likely to occur.
- Data generation: after being presented with a series of artwork, a neural network can learn how to produce new pieces in similar styles. This year Christie’s has sold the first piece of AI art for $432,500.
Neural Networks in Business: Real-world Examples in Different Industries
According to O’Reilly survey, in 2018 twenty-eight percent of businesses have already started using deep learning and 54% said that it would play a key role in the upcoming projects.
The race is officially on, and not just among the large tech companies (Google & Facebook). A number of trailblazing enterprises and innovative startups across several industries have joined the bandwagon as well.
Cybersecurity
Clearly, 2018 has given us a lot of lessons in terms of online privacy and security. Hackers are becoming more sophisticated with their tools and techniques; whereas product owners struggle to locate and “patch” the key vulnerability areas within their jumbo-sized products, without over-complicating user-experience.
Deep learning can be a game-changer for the online security sector as NN-powered algorithm can self-optimize over time and learn to predict, recognize and mitigate emerging threats before they occur. Deep Instinct – an Israel-based startup is working on such solutions.
Agriculture
Agriculture is becoming more data-driven as well. Deep learning has a massive potential here in terms of process optimization and crop planning. Such models can effectively predict how different factors will impact crop yields. Descartes Labs is attempting to conduct such predictions on a global scale.
Social Media and Publishing
LinkedIn leveraged neural networks to create better content classification mechanisms and deliver better recommendations to users. They also deploy NNs to locate spam and abusive content shared on the newsfeed.
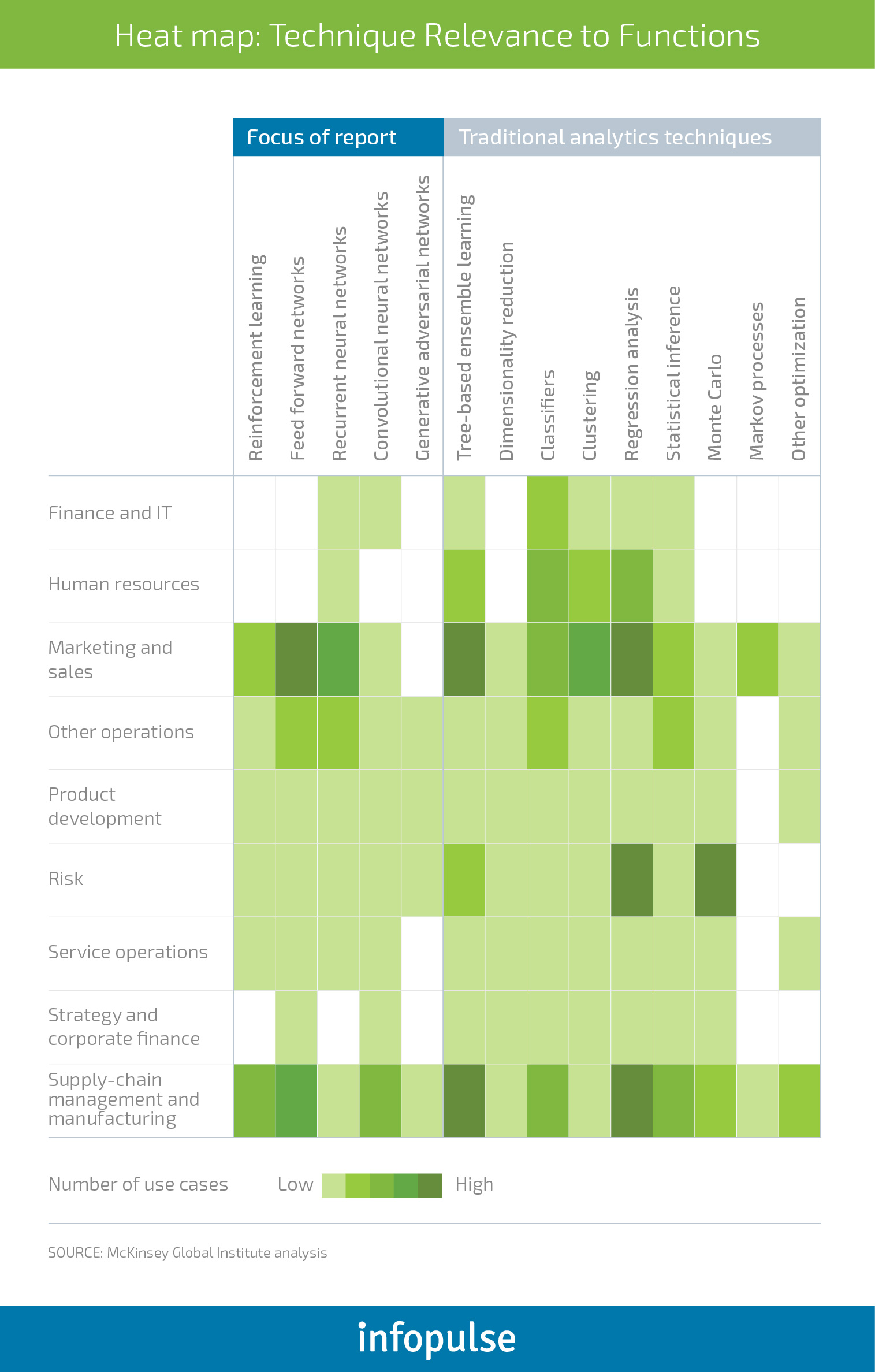
In the “Notes from the AI frontier” report, McKinsey proposed the following heat map indicating how neural networks and deep learning can be used across different business functions:
The Business Case for Investing in Deep Learning and Artificial Neural Networks
McKinsey also estimates that deep learning and neural networks have the potential to enable an additional $3.5 trillion to $5.8 trillion in value annually across 9 business functions (visualized in the previous section) in 19 industries.
DL can cast a transformational effect on how businesses currently approach analytics and help unlock additional insights by capturing and analyzing new types of data. According to O’Reilly, businesses are mostly interested in the following use cases for neural networks and deep learning:
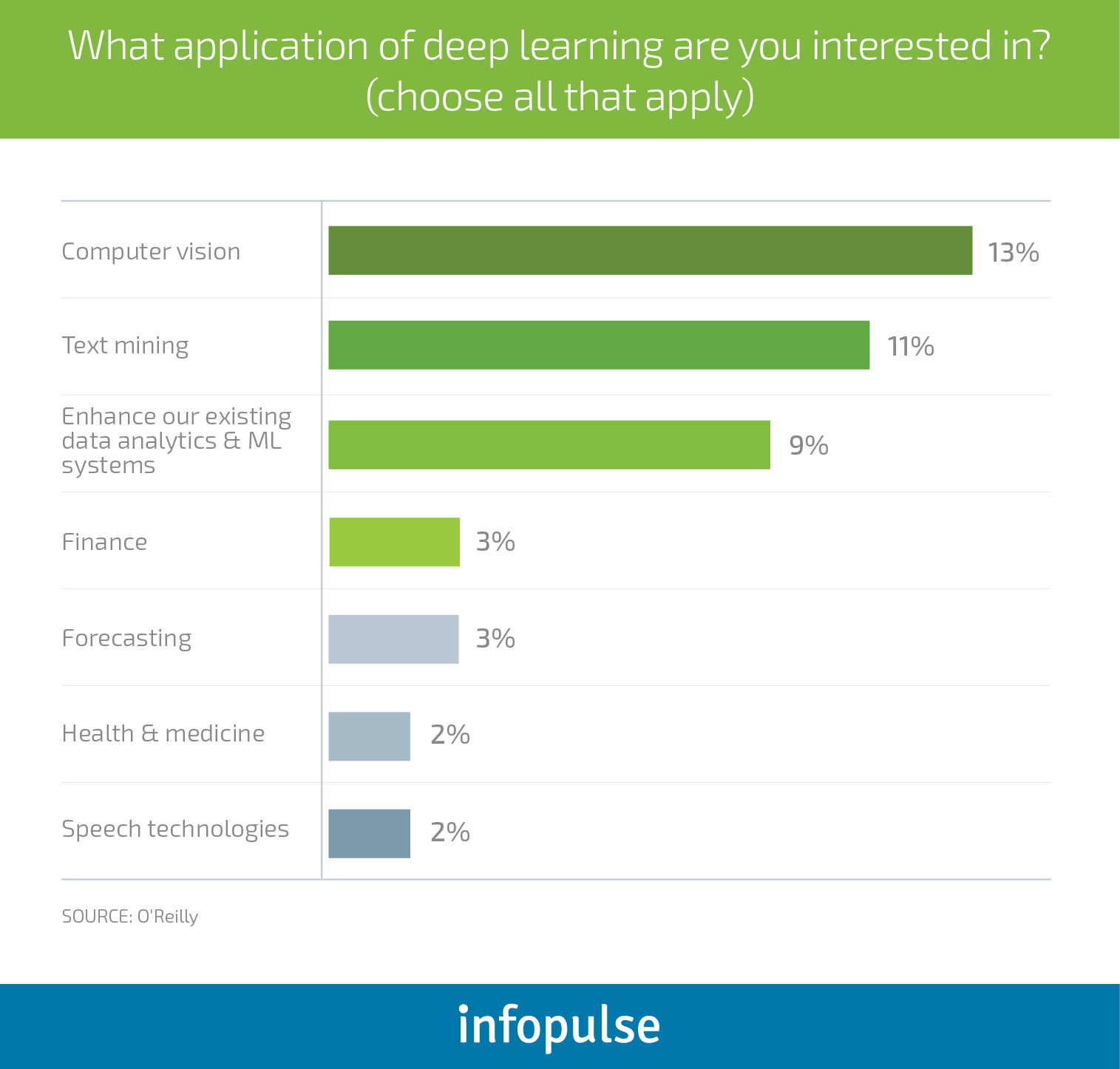
Computer vision alone can enable a series of transformational use cases including self-driving vehicles; micro-robotic tools and gadgets for medicine; advanced medical diagnostic procedures; advanced monitoring and analysis for the agriculture industry and new-gen bio-authentication mechanisms for the fintech industry.
For tech giants like Amazon, Facebook and Google it’s no longer the question of why use neural networks in the first place – it’s how to capture even more benefits of deep learning and apply them towards existing business processes.
The cumulative benefits of neural networks can be summed up as this: making any digital processor experience feel more human. Machines have already been taught to recognize human expressions and deliver personalized travel experiences. DL algorithms already have a higher accuracy rate when it comes to speech recognition and complex image recognition tasks, e.g., cancer cell detection.
Neural networks can operationalize large volumes of data at a scale nowhere close to the human’s abilities. This means that multiple tasks could be effectively automated; new insights can be uncovered with the help of large-scale analysis and digital transformations can be effectively deployed based on that data and automation. In fact, only 8% of business executives believe that deep learning won’t play any role in their future projects.
So, why is there disparity between the willingness to adopt and the actual adoption rates of DL? The process of developing neural networks requires significant resources in terms of hardware, niche expertise, and data.
The Common Adoption Bottlenecks for Deep Learning and Artificial Neural Networks
Data
Data requirements for deep learning are greater than for any other type of machine learning. But the problem is that not every type of data will suffice for designing a neural network. Training data sets should be diverse and properly labeled, turning the data collection into a mini-business project of its own.
Relying on insufficient data can majorly eschew the accuracy of your network – it could learn to spot the wrong patterns. In one experiment, scientists were training a neural network to distinguish between images of dogs and wolves. The network was giving surprisingly accurate results within a short timeframe. The wrinkle? It was producing good results due to biased data – the training dataset included undesirable correlations that then network picked. All the photos with wolves usually had snow in the background (white area), whereas dog images did not. When given a picture with a dog sitting on snow, the network would classify it as a wolf. The bottom line: data collection and refinement process is utterly important for developing high-performing algorithms.
Lack of expertise
20% of companies name the “skill gap” as their main bottleneck for deep learning adoption. Data scientists with relevant background and skill sets are scarce and already in high demand. The solution? Companies are now actively investing in AI training for employees and reskilling programs, not just for development teams. Business executives should also look into developing a better grasp of AI disciplines to effectively identify when to use neural networks within their organizations, and manage more diverse technical teams. If the talent is hard to attract locally, companies should also look into building partnerships with external service providers, already well-vested in the AI domain. This way, you can unlock immediate access to innovation without wasting time or budgets on headhunting or training your existing teams.
Legacy infrastructure
Feeding the network with large volumes of relevant data will also require significant hardware resources and GPU-grade computing, which can upsurge the total ownership costs of running a DL project. Each new layer added to the network makes it more “intelligent” and also upstreams the consumption of computing power. More layers translate to better outcomes up till the point when the costs of adding a new one become prohibitive.
Additionally, to accommodate new AI-powered processes, companies should look into transforming their legacy software-defined infrastructures (SDIs) to AI-defined infrastructures (ADIs) and elastic cloud-based solutions that can accommodate the changing business needs.
On a brighter side, businesses can reduce costs on software, as the best deep learning frameworks are open-source.
The Best Free Open-Source Deep Learning Frameworks to Use for Your Business
Towards Data Science has been recently conducted a survey, to measure a cumulative power score for different deep learning frameworks, derived from each frameworks’ usage stats, interest and popularity.
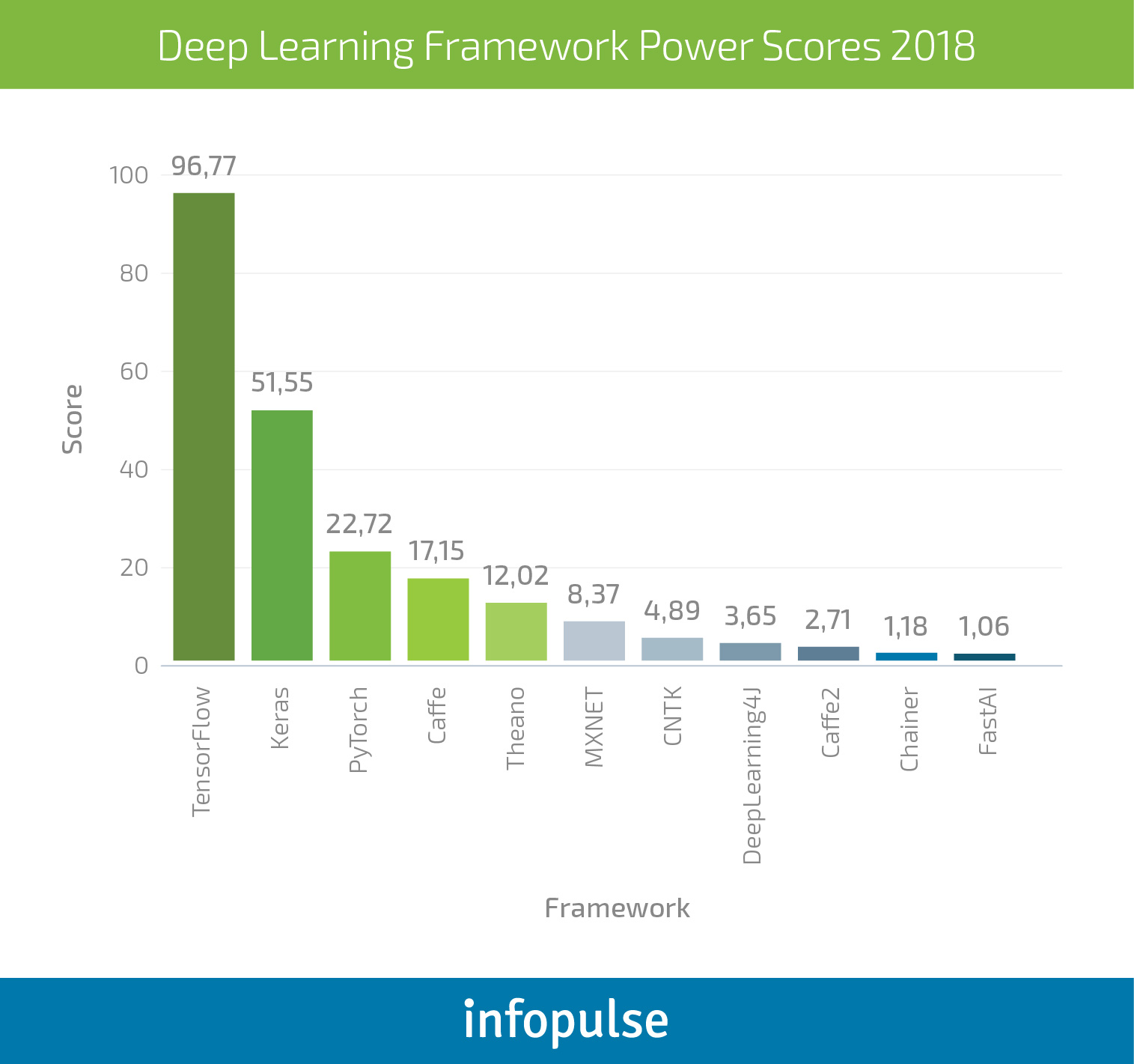
TensorFlow
TensorFlow is the obvious contender for most deep learning professionals. Backed and developed by Google, this framework has been used by the likes of Twitter, Airbnb, SAP, Intel, and a selection of other progressive companies.
If you have noticed how Google Translate service has majorly improved this year, it is all thanks to the company’s adoption of a new neural network NLP (Natural Language Processing) approach. By leveraging TensorFlow, Google enabled more accurate translation services, including on-the-spot voice translations.
The two key tools businesses can largely benefit from are:
- TensorFlow Serving enables rapid deployment of new algorithms/experiments while retaining the same server architecture and APIs. Meaning that your models can be rapidly and securely connected to your business systems for real-time experiments. This tool also enables integration with other TensorFlow models and can be extended to serve other models and data types, you have created using another framework.
- TensorBoard offers comprehensive data visualization tools that help optimizing and debugging complex neural networks, and other models built with the tool.
Currently supports the following client languages: Python – best support; partial and community-led support – C++, Java, Go, Scala, Ruby, C#.
Keras
Keras is a neural network API library, designed primarily for Python. Best suited for designing convolutional and recurrent neural networks (multi-layer, complex architectures) that you plan to run on top of TensorFlow, CNTK (from Microsoft) or Theano. In fact, this tool emerged as UI-friendlier option to TensorFlow.
The main competitive advantage of Keras is modularity, enabling a “plug-and-play” approach to designing neural networks. The key elements of any network – neural layers, cost functions, optimizers, etc. – can be used and re-used as standalone modules for multiple models.
PyTorch
PyTorch is the closest competitor to TensorFlow. Developed as a port to an earlier Torch framework – a scientific computing network supporting machine learning algorithms – PyTorch is the newer version designed specifically for constructing deep neural networks. It runs on Python, supports C++ interfaces and comes with an extensive ecosystem of community-built tools and libraries. The framework is also well supported on all major cloud platforms; offers greater process visibility thanks to a hybrid front-end and allows distributed training.
PyTorch was largely backed and developed by Facebook’s AI research group and Uber probabilistic programming team, who used it for their “Pyro” software.
Caffe
Caffe is the fourth most popular choice. It supports more interfaces including C, C++, Python and MATLAB, plus command line interface. The biggest competitive advantage of this framework is that you can use pre-trained convolutional neural networks from their repository (Caffe Model Zoo) with little-to-no customization. Caffe is primarily used for image recognition tasks as it can process over 60 million images on a daily basis thanks to fast USP speed. The con, however, is that it does not support fine-granular network layers – like the ones you can build with TensorFlow or PyTorch. Building an NLP neural network using Caffe isn’t the best route either as its language modeling capabilities are rather modest.
Additional options:
- Theano is the oldest available deep learning framework, gradually losing its popularity due to the creator’s decision to stop developing it further. Though the community has made some new updates since.
- MXNET – a joint project by Apache and Amazon. The company uses MXNET as their reference library for deep learning. Supported by Python, R, C++, and Julia.
- CNTK is the Microsoft Cognitive Toolkit. It allows creating both RNN and CNN types of neural networks, meaning you can effectively tackle handwriting, speech and image recognition tasks. Supported by Python, C++, and the command line interfaces.
- ML.NET – a new open-source machine learning library for .NET developers, supporting C#, F# and VB.NET programing languages (released in spring 2018). Originally backed by Microsoft Research, the library is now gaining support among .NET developers. While it’s not as robust and comprehensive as other options, it’s a great entry point for those who want to develop basic ML models without retorting to Python. So far the library is well-suited for tasks such as binary classification, multi-class classification, anomaly detection and recommendation engines, new deep learning capabilities are said to be released within next updates.
Bonus Point: Rosetta Stone for Deep Learning Frameworks – a new project released by Microsoft team allows data scientists to “port” their expertise from one framework to another with less hassle, thus using different frameworks depending on the task at hand.
No matter which framework you choose and what use case of deep learning you plan to pursue, always begin your journey with a simple analysis. Probe the issue at hand using different machine learning tools, before setting the course for deep learning. This way you can ensure that you have a strong business case for adopting this technology and save yourself from launching a costly DL-project that will flop somewhere at the data labeling stage.
Infopulse expert team would be delighted to provide further executive guidance on AI-adoption aligned with your business goals and current technical capabilities. Let us explore together how your business can accelerate growth using novel tech stacks.
![Pros and Cons of CEA [thumbnail]](/uploads/media/thumbnail-280x222-industrial-scale-of-controlled-agriEnvironment.webp)

![Power Platform for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-power-platform-for-manufacturing-companies-key-use-cases.webp)
![Agriculture Robotics Trends [Thumbnail]](/uploads/media/thumbnail-280x222-what-agricultural-robotics-trends-you-should-be-adopting-and-why.webp)
![ServiceNow & Generative AI [thumbnail]](/uploads/media/thumbnail-280x222-servicenow-and-ai.webp)

![Data Analytics and AI Use Cases in Finance [Thumbnail]](/uploads/media/thumbnail-280x222-combining-data-analytics-and-ai-in-finance-benefits-and-use-cases.webp)
![AI in Telecom [Thumbnail]](/uploads/media/thumbnail-280x222-ai-in-telecom-network-optimization.webp)

