![Big Data Platform on AWS [banner]](https://www.infopulse.com/uploads/media/banner-1920x528-aws-data-platform-20230227.webp)
AWS im Kern: Ideales Lösungspaket zum Einrichten einer Big Data-Plattform
Grundsätzlich sieht sich jedes Unternehmen, das seine Kerndaten und -prozesse in die Cloud verlagert, mit gewissen Problemen konfrontiert: Für welchen Anbieter soll man sich entscheiden? Wer bietet die kosteneffizienteste Service-Suite für die Verarbeitung großer Datenmengen? Wie kann sichergestellt werden, dass die technischen Teams und die Benutzer in den Unternehmen mit der Wahl zufrieden sind? In unseren vorherigen Beiträgen haben wir bereits beschrieben, was Microsoft Azure und Google Cloud Platform tun können, um diese hohen Anforderungen und Standards zu erfüllen.
Jetzt ist es an der Zeit, die Angebote von Amazon Web Services in dieser Richtung zu untersuchen. Als echter Marktführer bei der Bereitstellung hoch skalierbarer, langlebiger und effizienter Cloud-Infrastrukturen hält AWS mit 34 % den größten Marktanteil und führt damit das Ranking der Top-3-Cloud-Infrastrukturanbieter laut Synergy Research an.
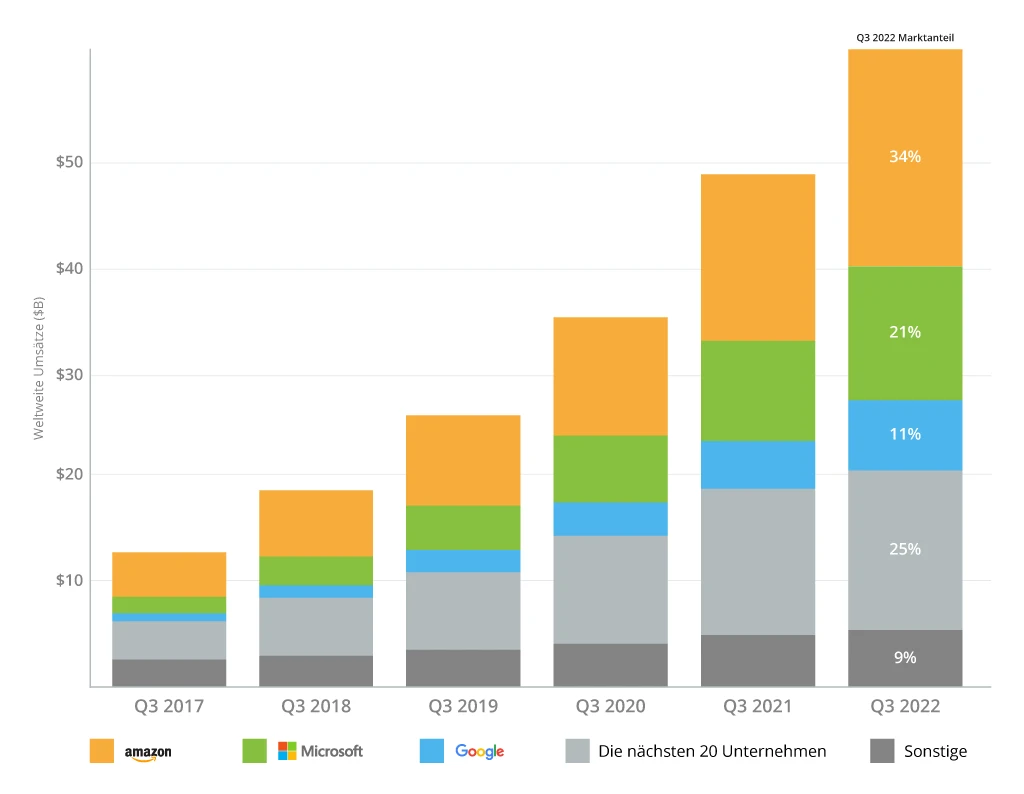
In diesem Beitrag erhalten Sie einen Überblick über die Fähigkeiten von AWS im Bereich Big Data, wie gut AWS die Anforderungen von Unternehmen erfüllt, die mit großen, hochgradig vernetzten Datensätzen arbeiten, und welche erfolgreichen Unternehmen sich für AWS entschieden haben, um ihre Kernlösungen zu modernisieren
Was Sie über AWS 3V-Parameter wissen sollten
Beim Aufbau einer Big-Data-Plattform auf AWS empfiehlt Infopulse die Verwendung von Cloud-basierten Lösungen, die den drei V-Parametern von Big Data - Volumen, Geschwindigkeit und Vielfalt - tatsächlich entsprechen. Vergleichen wir, wie die wichtigsten Datenspeicher- und Analyseangebote wie Amazon S3, Redshift, Neptune, Athena und Aurora die Anforderungen der Big Data-Verarbeitung erfüllen.
Datenvolumen (Datenmenge) - in S3 ist die Menge der gespeicherten Daten und Objekte unbegrenzt (allerdings darf die Größe jedes Objekts in einem Bucket 5 TB nicht überschreiten), während Redshift bis zu 16 Petabyte und Aurora bis zu 128 Terabyte zuweist.
Datengeschwindigkeit (Geschwindigkeit der Datengenerierung und -verarbeitung) - S3 erlaubt standardmäßig 5500 Anfragen pro Sekunde (bei Bedarf kann die Zahl auf bis zu 55.000 Leseanfragen skaliert werden) und ist in der Lage, Millionen von Objekten pro Abfrage zu scannen; Amazon Neptune kann über 100.000 Abfragen pro Sekunde verarbeiten. .
Datenvielfalt (strukturierte, halbstrukturierte, unstrukturierte Datensätze) - S3 ist in der Lage, jede Art von Daten zu speichern, die aus heterogenen Quellen stammen, während Amazon Athena die Verarbeitung aller drei Arten von Datensätzen und verschiedener Datenformate (z. B. Apache ORC, JSON, CSV, Apache Avro usw.) usw. unterstützt.
Lassen Sie uns nun die Leistungsfähigkeit der am häufigsten nachgefragten AWS-Services für den Aufbau einer Big Data-Plattform näher betrachten. Zusammen bilden sie ein leistungsfähiges Ökosystem an Diensten, die eine hohe Skalierbarkeit, Sicherheit und Automatisierung von Lösungen für die Speicherung und Verwaltung wichtiger Daten ermöglichen.
Amazon Web Services Toolkit zur Einrichtung einer Big Data-Plattform
Ein Beispiel für die Architektur einer Big Data-Plattform auf AWS
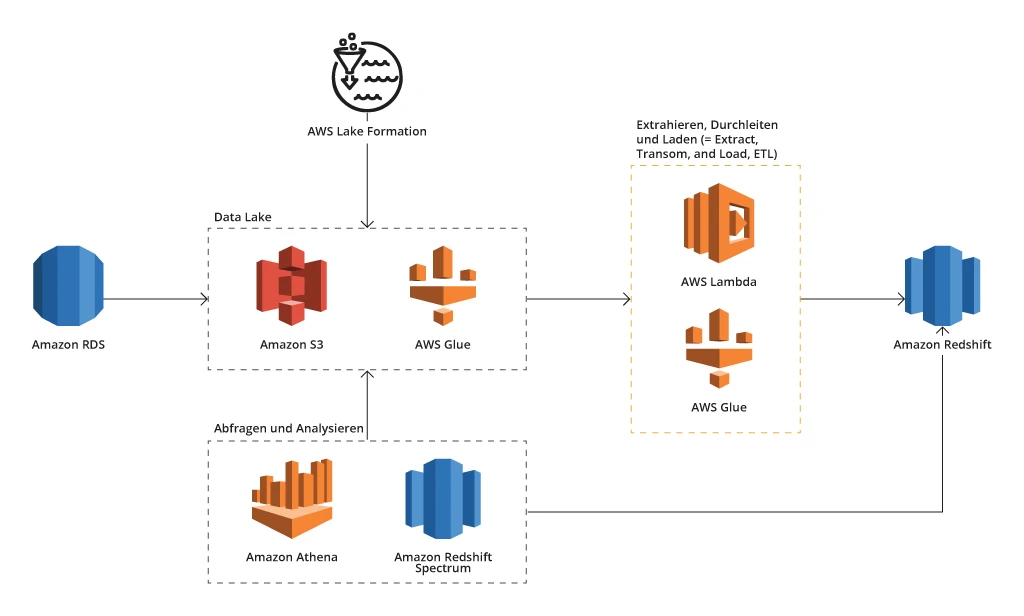
Amazon S3 (Simple Storage Service, also Einfacher Speicherdienst)
Jedes Big Data-Projekt mit AWS als Kernstück sollte auf Amazon S3 als Hauptobjektspeicher beruhen. Dies ist besonders beim Aufbau eines Cloud-basierten Data Lake nützlich. In den über 16 Jahren, in denen Amazon S3 auf dem Markt ist, wurden dort mehr als 100 Billionen Objekte gespeichert. Sie können sich also den Umfang dieses unbegrenzten Speichers vorstellen.
S3 wurde auf dem Entwicklungspfad von Amazon.com auf Zeit- und Spitzenlast getestet und hat sich zu einem robusten Dateispeicher im Petabyte-Bereich entwickelt. Jedes Objekt kann bis zu 5 TB an Daten enthalten und wird in einem separaten Bucket abgelegt. In diesen Buckets können buchstäblich alle Arten von Daten aufbewahrt werden - relationale (strukturierte), halbstrukturierte, unstrukturierte, z. B. Bilder, Videodateien, in ihren Originalformaten.
Der Datenzugriff ist standardmäßig gesichert, während der Prozess des Datenabrufs und der weiteren Analyse durch leicht integrierte Amazon-Services wie AWS Lambda, AWS Neptune, AWS Redshift usw. vereinfacht wird. Amazon S3 erfüllt mit einer Beständigkeit von 99,9999999 % und einer Datenverfügbarkeit von 99,99 % auch die Anforderungen an Zuverlässigkeit, Leistung und Geschäftskontinuität vollständig.
Durch die Entkopplung von Speicher- und Rechenleistung minimiert S3 die Kosten und die für die Ausführung komplexer Workloads erforderlichen Ressourcen und bietet gleichzeitig ein Höchstmaß an Flexibilität und Skalierbarkeit, da Sie sich einfach für die erforderlichen Speicherressourcen unabhängig von der Rechenkapazität entscheiden können. Außerdem helfen das Pay-as-you-go-Modell von S3 und seine Speicherklassen, die auf die Häufigkeit und Unmittelbarkeit des Speicherzugriffs ausgerichtet sind, dabei, Big Data nutzen zu können, ohne dabei Ihr Budget zu sprengen. Übrigens: Der beliebte Online-Marktplatz Airbnb setzte auf S3 und seine Speicherklassen, um seine Data Warehouse-Kosten um fast 27 % zu senken.
Amazon Athena vs. Amazon Aurora
Beide Dienste können zur Abfrage großer, in Amazon S3 gespeicherter Datensätze verwendet werden, funktionieren jedoch unterschiedlich. Amazon Athena ist in erster Linie ein serverloser interaktiver SQL-basierter Abfrageservice, der ein separates Data Warehouse und ETL überflüssig macht. Anstatt Daten aus S3 zu laden, führt Amazon Athena analytische Abfragen direkt in S3 aus, wodurch die Ergebnisse in wenigen Sekunden abgerufen werden können. Durch das Fehlen eines Servers kann die Bereitstellung der Infrastruktur übersprungen werden. Kosteneffizienz kann auch dadurch erreicht werden, dass nur die Abfragen bezahlt werden, die Sie tatsächlich durchführen
Amazon Aurora, eine relationale Datenbank mit MySQL- und PostgreSQL-Kompatibilität und automatischer Skalierung bis zu 128 TB, gewährleistet den schnellen und einfachen Export/Import von Daten in und aus S3. Wenn Sie sich für Aurora als Big-Data-Datenbank entscheiden, sollten Sie wissen, dass Aurora sich nahtlos mit Analysesystemen wie Amazon Redshift (nach dem Null-ETL-Prinzip) und Amazon QuickSight integrieren lässt. Darüber hinaus ermöglichen die Rechenleistung und der hohe Durchsatz von Aurora die parallele Ausführung von analytischen und transaktionalen Abfragen und gewährleisten ein Höchstmaß an Leistung und Skalierbarkeit. Atlassian nutzte Amazon RDS zusammen mit Aurora PostgreSQL, um die Skalierbarkeit zu erhöhen und mehr als 25 000 Benutzer für jeden Mandanten zu hosten.
Was die Kostenreduzierung angeht, so sprechen die Ergebnisse der praktischen Umsetzung für sich. Samsung beispielsweise konnte seine monatlichen Betriebskosten um 44 % senken, als das Unternehmen sein stark monolithisches DWH auf Amazon Aurora PostgreSQL umstellte.
Amazon Neptune
Als vollständig verwaltete Graphdatenbank, die Milliarden von Beziehungen in nur wenigen Millisekunden abfragen kann, kann Amazon Neptune eine wertvolle Komponente Ihrer AWS-Datenplattform werden. Neptune erleichtert den Umgang mit großen, miteinander verknüpften Graphdatensätzen. Diese Datenbank unterstützt gängige Graphenmodelle und Standardabfragesprachen wie Gremlin, SPARQL und openCypher.
Darüber hinaus ist auch eine Python-Integration verfügbar, die die Analyse von Graphdaten und die Ausführung von Machine-Learning-Algorithmen anregt. Letzteres kann ein gutes Sprungbrett für trendige Anwendungsfälle wie den Aufbau einer Empfehlungsmaschine, Betrugserkennung, verbessertes Sicherheitsmanagement, vorausschauende Analysen usw. sein. Ein weiteres Merkmal, das belastbare Unternehmen heutzutage sehr schätzen, ist die Fehlertoleranz und Selbstreparaturfähigkeit von Neptune dank der Unterstützung von fast 15 Lese-Replikaten, die über drei Availability Zones verteilt sind. Letzteres trägt auch zu der 99,99%igen Verfügbarkeit von Amazon Neptune bei.
Weiter unten finden Sie eine Fallstudie aus der Praxis, die zeigt, wie Infopulse eine Datenplattform für ein großes Wirtschaftsprüfungs- und Beratungsunternehmen aufgebaut hat, das unter anderem Amazon S3 und Amazon Neptune nutzt.
Amazon Redshift
Als Teil der Analyseschicht optimiert dieses vollständig verwaltete Cloud-Data-Warehouse mit spaltenförmiger Speicherung den Datenabruf und die analytische Abfrage erheblich. Da die Geschwindigkeit bei der Verarbeitung von Big Data entscheidend ist, ist Redshift mit einer massiven Parallelverarbeitung ausgestattet und in der Lage, Datensätze im Petabyte-Bereich zu verarbeiten, die aus einer Vielzahl von Quellen stammen. Amazon Redshift ermöglicht das Sammeln und Analysieren ausschließlich strukturierter oder halbstrukturierter Daten, um Datenanalysten und Geschäftsanwendern zu helfen, wertvollere Erkenntnisse zu gewinnen. Es gibt jedoch eine Möglichkeit, das Potenzial unstrukturierter Daten durch die Integration von Redshift mit S3 zu erschließen.
Ebenso wie andere Repository-Angebote von Amazon automatisiert Redshift auch die Bereitstellung der Infrastruktur und administrative Aufgaben wie Backups, Replikation, Überwachung usw.
Ein typisches Beispiel: Nasdaq, ein internationales Finanz- und Technologieunternehmen, nutzte Amazon S3 und Amazon Redshift, um die erforderliche Skalierbarkeit und Flexibilität seiner Data-Lake-Lösung beim Einlesen von bis zu 113 Millionen Datensätzen pro Tag zu gewährleisten.
Eine weitere wertvolle Funktion von Redshift ist die Erstellung von Machine-Learning-Modellen. Redshift arbeitet mit Amazon SageMaker zusammen, einem umfassenden Service für das Training eines ML-Modells. Mit Daten aus Redshift können Sie einfache ML-Modelle verwenden, trainierte Modelle mit SageMaker automatisch einsetzen und eine Vorhersage erstellen. In diesem Fall kann das ML-Modell leicht auf Daten angewandt und in Abfragen, Dashboards und Berichte integriert werden, um die prädiktive Analyse für verschiedene Anwendungsfälle zu vereinfachen, z. B. Vorhersagen zu Umsatz und Wartung von Geräten/Systemen, Risikobewertung, Betrugserkennung, Abwanderungsvorhersage usw.
AWS Glue
AWS Glue ist ein moderner ETL-Service, der die Erkennung, Vorbereitung und Verschiebung von Daten aus mehr als 70 heterogenen Datenquellen vereinfacht. AWS Glue ist eng mit seiner Kernkomponente Data Catalogue verbunden, die Metadatenquellen und -ziele speichert. Zum Verschieben solcher Daten von einer Quelle zu einem Ziel führt AWS Glue Aufträge aus, die für die Ausführung von ETL-Skripten entweder mit Apache Spark für die Verarbeitung von Daten in Stapeln oder Datenströmen oder mit einer Python-Umgebung (insbesondere Python-Shell-Aufträge zum Extrahieren von Quelldaten außerhalb von AWS) eingerichtet sind. Insgesamt sorgt AWS Glue für robuste ETL-Prozesse und nahtlose Datenintegration durch automatische Datenklassifizierung, -kategorisierung, -bereinigung, -umwandlung und vertrauenswürdige Übertragung.
AWS Lambda
Dieser serverlose Rechenservice fungiert als Trigger für über 200 AWS-Services und ermöglicht es dem System, einen Code für verschiedene Apps und Backend-Services auszuführen, ohne dass Server bereitgestellt und verwaltet werden müssen.
AWS Lake Formation
Der Aufbau eines Data Lake mit AWS Lake Formation kann innerhalb weniger Tage erfolgen, wodurch viele arbeitsintensive und zeitaufwändige Datenverwaltungsvorgänge vereinfacht und beschleunigt werden. Durch die zentrale Verwaltung von Daten aus allen verfügbaren Quellen spielt AWS Lake Formation auch eine entscheidende Rolle bei der Metadaten- und Datenzugriffskontrolle und ermöglicht so deren Sicherheit und Zuverlässigkeit.
Anwendungsfall aus der Praxis: Eine Big Data-Plattform auf AWS für über 100.000 Benutzer
Was der Kunde benötigte
Unser Kunde, eine große Wirtschaftsprüfungs- und Beratungsgesellschaft, erbringt professionelle Dienstleistungen (Wirtschaftsprüfung, Steuern, Beratung) für zahlreiche Unternehmen in aller Welt. Der Kunde verfügte über ein umfangreiches Netz von unterschiedlichen Kontakten und deren Interaktionen innerhalb und außerhalb jedes Unternehmens. Die Daten zu diesen Kontakten lagen in heterogenen Systemen vor und waren in den meisten Fällen nicht konsistent. Um alle Kontakte an einem Ort zu sammeln und alle ihre Beziehungen abzubilden, beschloss das Wirtschaftsprüfungsunternehmen, eine zentrale Datenplattform einzurichten, die diese Daten vereinheitlicht und es den Nutzern ermöglicht, einfach auf sie zuzugreifen und zu handeln. Der Kunde beauftragte Infopulse als langjährigen Partner und erfahrenen Anbieter von komplexen Datenanalyseprojekten.
Welche Lösung bot Infopulse an?
Infopulse entwickelte eine Big-Data-Plattform, die auf AWS-Analysediensten basiert, um eine robuste Datenaggregation zu ermöglichen - über 100 Millionen Datensätze, einschließlich Finanz- und Kontaktdaten aus verschiedenen Quellen. Bei den Datenquellen handelte es sich um verschiedene Systeme, die eine zusätzliche manuelle Bearbeitung erforderten, um Datenkonflikte, Duplikate, Inkonsistenzen oder andere Fehler zu erkennen, die eine einwandfreie Datenanalyse behinderten. Insgesamt wurde von Infopulse eine ausgeklügelte Lösungsarchitektur entwickelt und erfolgreich umgesetzt:
Architektur der AWS Big Data-Plattform
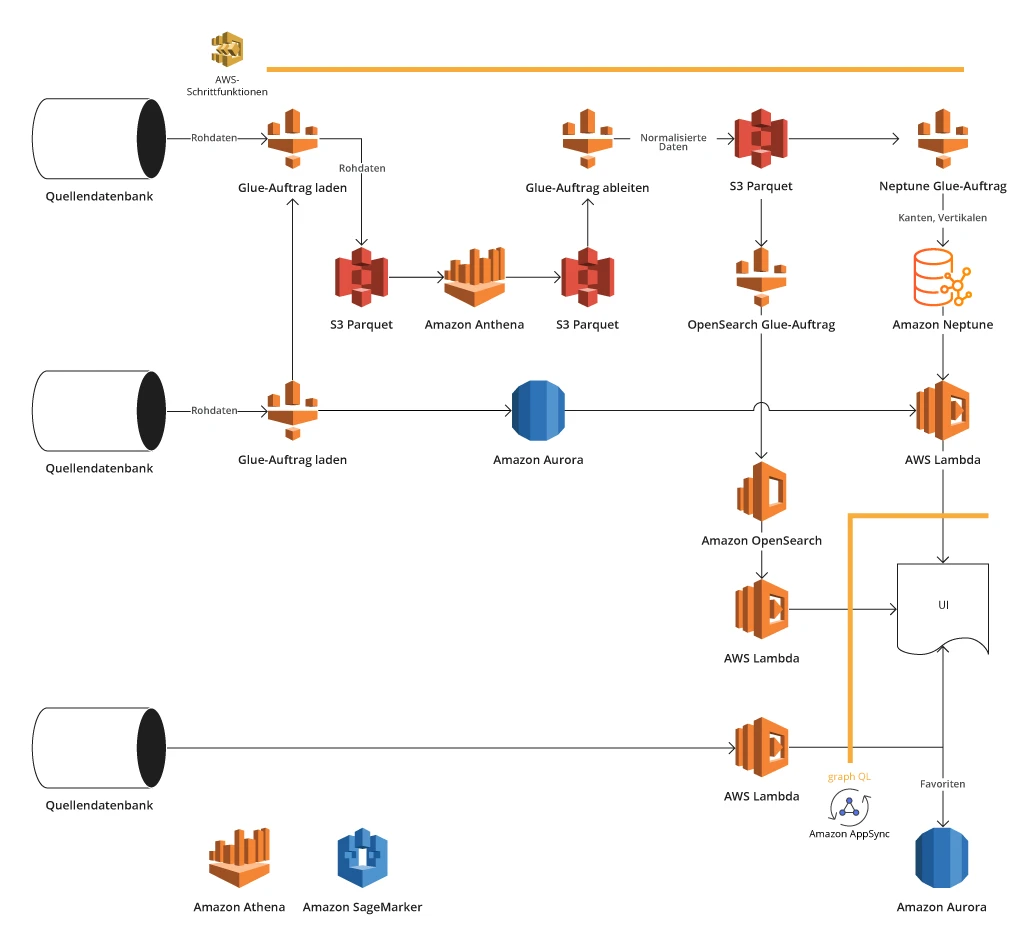
- Gewährleistete die Vereinheitlichung von Daten zur Beseitigung von Duplikaten und zur Verbesserung der Datengenauigkeit
- Ermöglichte die Analyse von Kontaktdaten in Bezug auf die Mitarbeiter von Kunden und deren Interaktionen mit anderen Abteilungen und Führungskräften
- Rief Daten aus heterogenen Systemen mit Hilfe von APIs, Dateireplikation, direktem Zugang zu Datenbanken von Systemen usw. ab.
- Speicherte große Mengen an Zwischendaten in einem Objektspeicher von Amazon S3, der dank seiner grenzenlosen Skalierbarkeit und hohen Ausfallsicherheit auch als Data Lake diente
- Benutzte Amazon Neptune, eine graphenorientierte Datenbank zur Speicherung wichtiger Kontakt- und Finanzdaten von Unternehmen, mit denen der Kunde zu tun hatte. Neptune eignet sich gut für den Aufbau eines Netzwerks von Kunden (Mitarbeitern, Managern usw.) und deren Beziehungen unter Berücksichtigung der verschiedenen beteiligten Parteien. Zur Erleichterung der Datenanalyse von Interaktionen setzte das Team jedoch auch Amazon Athena ein und integrierte dann Aurora als RDS-Datenbank, was die Speicherung großer Datenmengen ermöglichte und die Verarbeitung von Interaktionen beschleunigte
- Stellte die Datenumwandlung mit AWS Glue-Aufträgen sicher
- Automatisierte Datenverarbeitung ermöglicht eine schnellere Datenanalyse und damit verbundene Datenverwaltungsaktivitäten.
Welchen Wert erhält der Kunde?
- Durch die Konsolidierung aller Daten über die Kunden des Kunden und seine Mitarbeiter wurde ein goldener Rekord und eine zentrale Informationsquelle geschaffen.
- Die Datenqualität, ihre Vollständigkeit, Konsistenz, Genauigkeit und Zuverlässigkeit zu verbessern
- Der Datenzugriff für über 100 000 Geschäftsanwender eines Wirtschaftsprüfungsunternehmens wurde erleichtert (auch wenn Unterlagen gleichzeitig angefordert werden), was auch die Datenanalyse und die erkenntnisgestützte Entscheidungsfindung verbessert.
- Die Ermittlung von Beziehungen und Interaktionen zwischen verschiedenen Ansprechpartnern von Unternehmen, die Dienstleistungen der Prüfungsgesellschaft in Anspruch genommen haben oder noch in Anspruch nehmen, wurde vereinfacht. All dies verbessert die Kommunikation und Zusammenarbeit von Geschäftsanwendern erheblich.
- Automated data processing that prompts faster data analysis and related data management activities.
Sie fragen sich, ob diese Lösung auch Ihrem Unternehmen beim Aufbau einer effektiven Datenspeicher- und Analyselösung helfen könnte? Die branchenübergreifende Erfahrung von Infopulse ermöglicht es, fundiertes Fachwissen über AWS-Lösungen auf nahezu jeden möglichen Anwendungsfall anzuwenden. Wenn Sie bereit sind, über Ihre potenziellen Vorteile von AWS zu sprechen, dann beginnen wir doch einfach mit einem kleinen Gespräch.
Abschließende Punkte
Bei der Modernisierung Ihrer Datenspeicher- und Geschäftsanalyselösungen sollten Sie sich für die optimale Tool-Suite entscheiden, um eine effektive Datenerfassung, ETL-Prozesse, Datenanalyse, Visualisierung und Berichterstattung zu gewährleisten. Die Möglichkeiten von AWS scheinen unbegrenzt und verlockend für Big Data-Analysen. Um jedoch den größten Nutzen zu erzielen, sollten Sie über genügend Fachwissen verfügen, um zu verstehen, welche Datenbank- oder Datenverarbeitungslösung sich für Ihren speziellen Anwendungsfall eignet. Infopulse kann Ihnen dabei helfen und bietet professionelle AWS- und Datenanalysedienste an.


![Data Platforms on Azure [thumbnail]](/uploads/media/thumbnail-280x222-building-data-platforms-microsoft-azure.webp)
![Migration to Power BI [thumbnail]](/uploads/media/thumbnail-280x222-a-guide-to-power-bi-igration-5-stages-to-follow.webp)
![SAP SuccessFactors Learning Solution [thumbnail]](/uploads/media/thumbnail-280x222-sap-successfactors-learning-solution.webp)
![Talent Pool on SAP SuccessFactors [thumbnail]](/uploads/media/how-to-build-a-balanced-talent-280x222.webp)




