![Big Data Platform on Google Cloud Platform [banner]](https://www.infopulse.com/uploads/media/banner-1920x528-why-your-big-data-platform-should-reside-on-google-cloud.webp)
Why Your Big Data Platform Should Reside on Google Cloud
Businesses across all industries have learned their lesson and drifted from storing their data in spreadsheets to investing more in big data, BI software, and related IT services. According to IDC, both projected to account for $167 billion of investments in 2021.
Among the top cloud providers that enterprises choose for their big data management needs are AWS, Microsoft Azure, and Google Cloud Platform. We have already discussed the strengths and capabilities of Microsoft Azure in one of our recent blog articles Building Modern Data Platforms on Microsoft Azure. Now it’s the turn of Google Cloud to be put on display.
In this blog post, Infopulse, an IT services provider with the most extensive experience in implementing big data cloud solutions from AWS, Microsoft Azure, Google Cloud Platform, and SAP, attempts to facilitate the studying of Google Cloud Platform’s capabilities in building a powerful big data platform.
If you would like to read a quick overview of other data platform toolkits such as AWS and Microsoft, see the following blog article.
What Google Cloud Platform (GCP) Has to Offer in Big Data?
First off, let’s mention one quick fact that may also influence your decision whether to go for Google Cloud Platform (GCP) or not. In 2021, Google Cloud Platform as well as its strong competitors entered the Gartner’s Magic Quadrant as one of the leaders in cloud database management systems. Now, let’s look at the GCP’s overall capabilities that can become beneficial when building a big data platform.
GCP’s big data features and strengths:
- GCP is modular by design and simplifies big data solutions adoption
- A low-cost, fully managed, and serverless data warehouse that is created to ingest and process rapidly massive amounts of data (up to petabytes)
- Cost-effective big data storage solutions for raw unstructured data
- NoOps, no need to oversee the underlying infrastructure
- Ability to rapidly process all types of data — structured, semi-structured, or unstructured
- Immediate querying of streaming data
- Batch or real-time data stream processing
- Unmatched scalability of GCP depending on the growing data sets, etc.
Big Data Platform Toolkit Based on Google Cloud
BigQuery: Data Storage and Analysis
We will cut a greater piece of this “overview cake” to BigQuery as it is the backbone of the entire GCP platform.
The enterprise-level data warehouse that is designed for fast big data consumption, retrieval, and analysis actually resembles an artwork. Every detail is well-thought-out in its distinct architecture to stand the test of overwhelming volumes of data. To mention a few, the decoupled storage and compute engines, serverless infrastructure that is also fully managed, allow using resources cost-efficiently and with less effort needed. The latest research by ESG shows that BigQuery can ensure 27% lower TCO as compared to other top cloud providers. When comparing BigQuery’s functional capabilities, one sees how well it overcomes DWH management complexities, at the same time enabling integration with other cloud solutions to effectively move and analyze data from different clouds, including AWS and Azure.
Functional Comparison of Top Cloud-based Data Warehouses
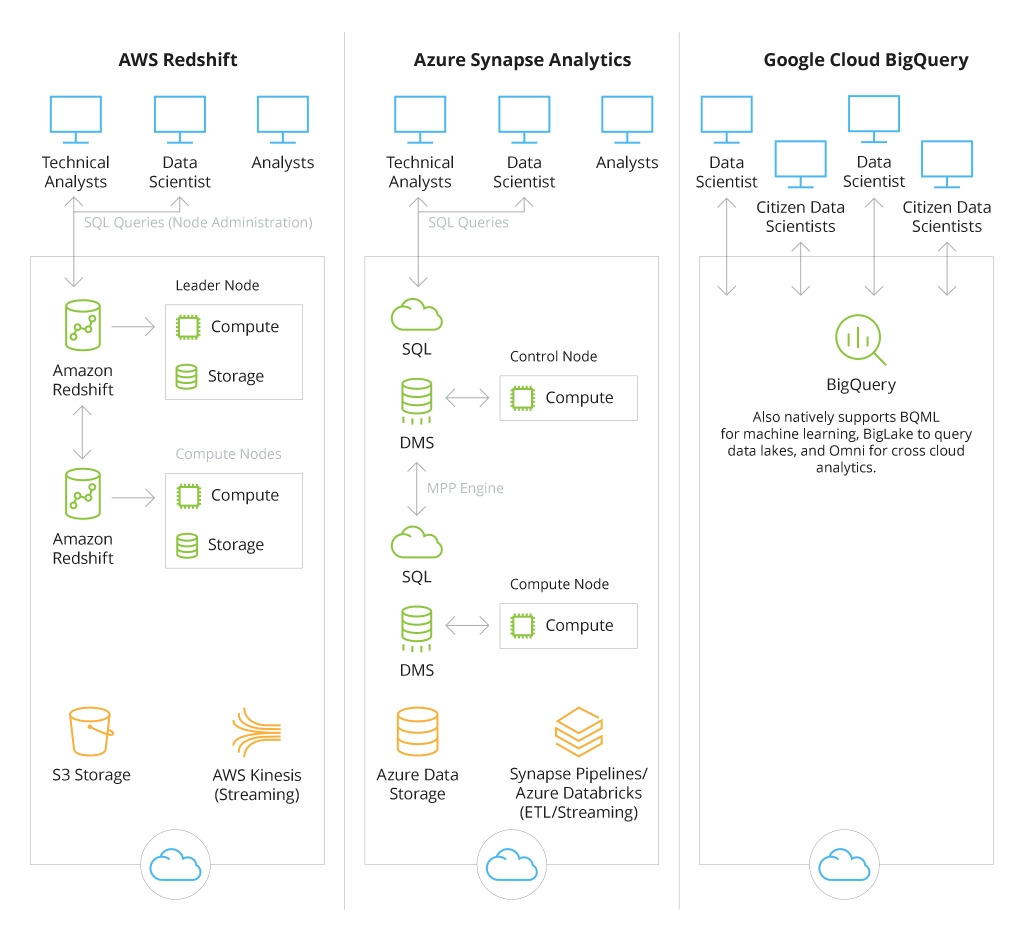
To handle immense and complex data sets, a data warehouse should have the corresponding capacities, such as:
Resilience and Availability
Due to the high redundancy of BigQuery’s storage and computing power, the availability of data is never threatened. When data is stored, it’s always duplicated in at least two other geographical zones (Google’s data centers) in a separate region. Moreover, such redundancy also spreads to the computing power across the related zones. What it means is that even if a machine or a complete data center fails, you may expect only milliseconds of delay in data querying.
Flexibility and Scalability
BigQuery’s flexibility is essential for the speed of data processing and analysis, especially for high-throughput data streaming scenarios. The split of storage and compute engines within the BigQuery’s architecture provides the necessary level of flexibility to scale them up/down individually depending on the current needs and demand. Moreover, BigQuery is self-scaling, meaning the system decides how many resources are needed to perform the query efficiently.
High Performance
Unlike traditional relational DWH, BigQuery is column-oriented (each column with table data is stored independently) which allows querying a specific record over a large dataset without the need to read each row of table data. As a result, you can almost instantly get to the needed piece of information and derive helpful insights faster. Another great feature that makes BigQuery architecture perfect for big data storage and processing is its in-memory query execution through distributed memory shuffle and using the petabit per second network Jupiter.
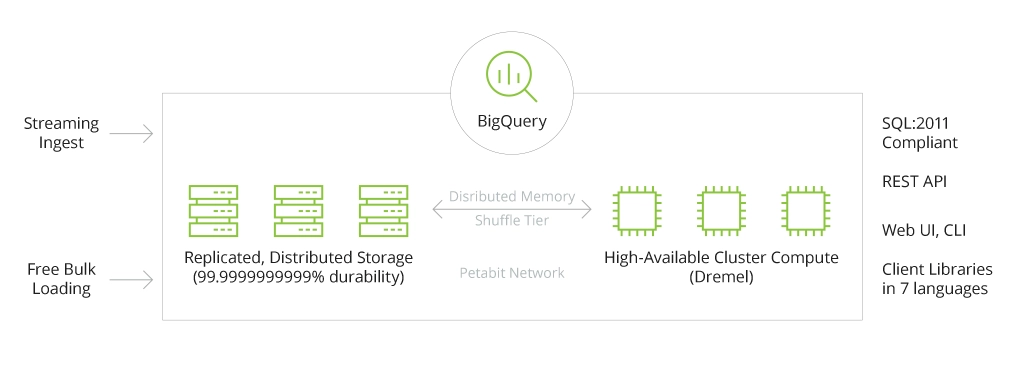
All this translates into fast petabyte-scale data movement and analysis. Also, to extract even more value at advanced speeds, BigQuery comes with built-in AI and ML capabilities to suffice a range of use cases for predictive analytics and maintenance, price forecasting, fraud and anomaly detection, and customer churn prediction.
Elasticity and Complete Management
The beauty of a fully elastic big data-oriented DWH is that it automatically decides how many compute resources will be necessary to perform a specific query to match the demand. Being fully-managed, all the administration tasks are automated and ergo, simplified.
Self-maintenance
Another strong point we want to single out is its ability to be “self” in almost every crucial aspect for modern DWH. Big Query’s infrastructure maintenance entirely resides on Google per se. There’s no need to maintain any physical or virtual hardware or DWH nodes, as well as to troubleshoot, monitor, patch, or update the storage, etc.
Cloud Storage
Unlike BigQuery, this object data repository suites best to rapidly build a cost-effective data lake for keeping an unlimited amount of raw, unstructured data and retrieving it at any time needed. Cloud Storage is simply used for storing and retrieval of big data sets in the cloud, further processed and analyzed in BigQuery, for example. The data (an object) is placed in a container called “bucket” with a defined geographic location. One object can be replicated in one, two, or multiple regions that allow for high geo-redundancy of the storage and overall data availability. Among other strengths are:
- High scalability — you can add as much space as needed to cover your changing needs
- High flexibility due to four essential storage classes based on the access frequency, budget expectations, and availability: Standard or regional (frequently accessed “hot” data), Nearline (data is accessed once a month), Coldline (once a quarter), Archive (once a year)
- Superior performance and 99.999999999% durability per year and low latency
- Security by design enabled with the encryption at rest or encryption with own keys using Key Management Service and permission-based access to the objects (for a member, a team, or public access), etc.
Google Cloud Storage in the Google Cloud Platform Ecosystem
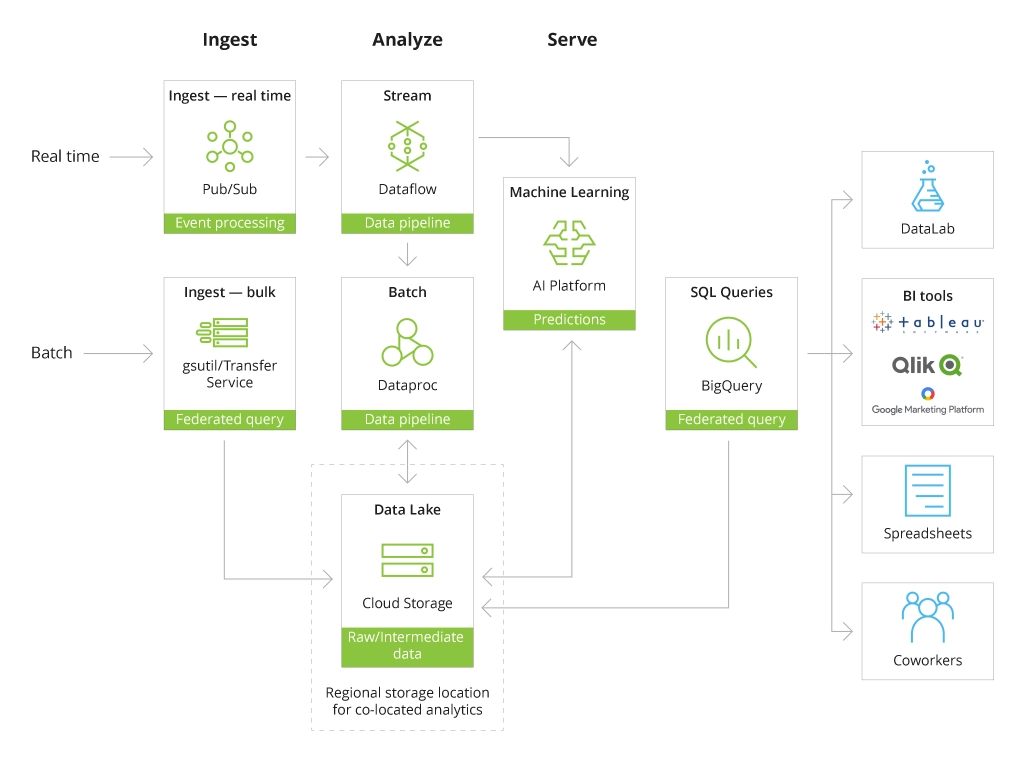
Google Kubernetes Engine
Since a big data platform requires optimal performance and resources efficiency, many businesses lean toward placing big data apps in containers further orchestrated with Kubernetes. One research found that in 2021, 77% of companies said they were about to move their workloads to containers with the help of Kubernetes.
Tried and tested with the rise of Google’s data-intensive apps like YouTube and Gmail through over 10 years, Google Kubernetes Engine (GKE) gained its confidence and trust among those who already had experience with the open-source Kubernetes system. The latter was also originally developed by Google, hence the same design principles were implemented in GKE, however as a managed service, it greatly simplifies and automates the deployment and management of containerized applications. Being both a container orchestrator and a management tool, GKE presents the needed level of automation, flexibility, and portability for data applications. To be more specific, let’s relate to a recent Forrester study, focusing on the GKE’s economic impact and specific benefits businesses got with GKE at hand:
- 35% less labor needed to set up the initial Kubernetes environment due to the default features and automation
- Decreased the current cluster management and optimization time by 75%
- Up to 30% increase in the developer productivity
- Staggering 75% reduction of infrastructure spending
- 80% higher efficiency of teams due to GKE’s automatic patching and release process
- Improved availability of storage, compute, and network resources by 97%
A case in point: When Infopulse helped a smart card production enterprise to build a custom cloud solution running on Kubernetes to mainly automate software delivery, the costs for development and support were reduced by 5X (from €100 to €20 million a year).
Cloud Pub/Sub
Pub/Sub is basically a messaging service for enabling seamless integration between different independent services within microservice or serverless architecture, as well as asynchronous communication between Google Cloud Platform services. This tool is especially useful for streaming analytics, allowing to quickly ingest and distribute large volumes of data (including real-time data) to BigQuery, Dataflow, data lakes, etc. Overall, you can use Pub/Sub in the following use cases:
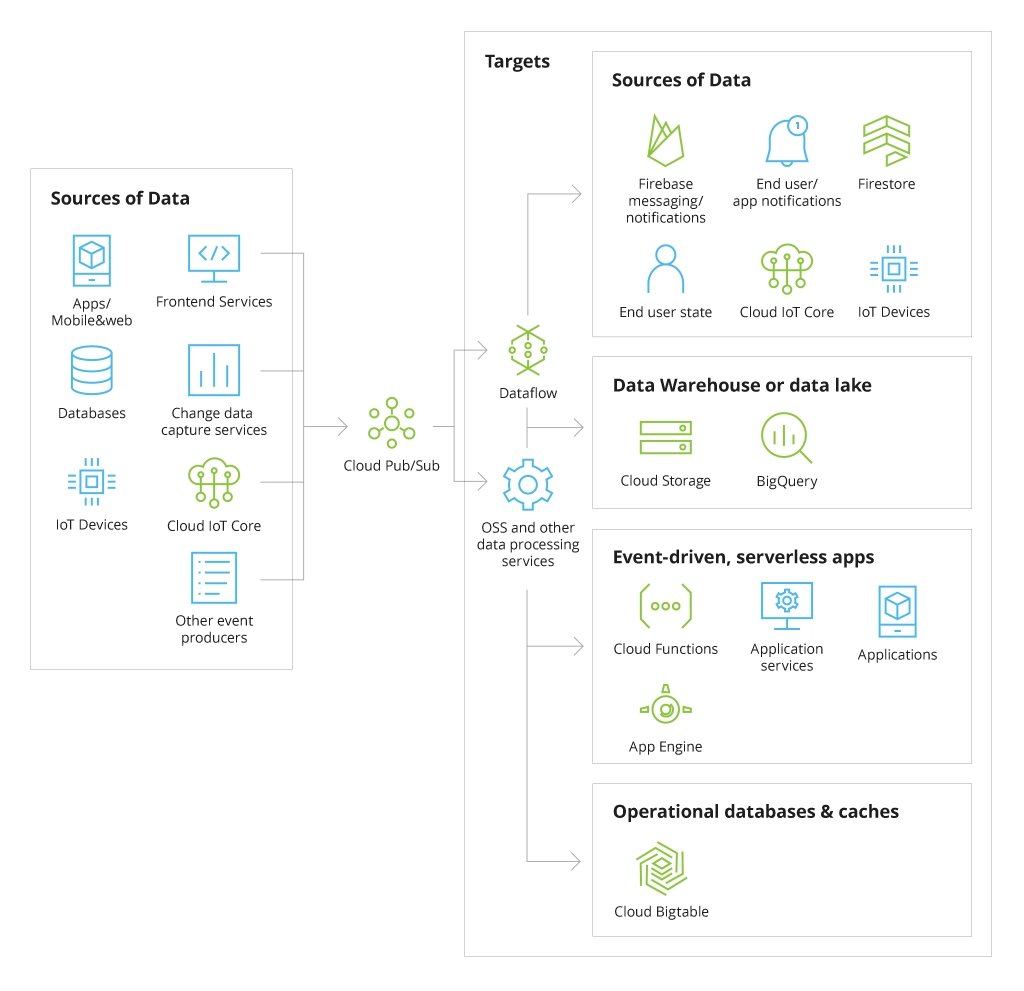
- Gathering user interaction events and server events from multiple systems simultaneously. These events can be further delivered to BigQuery, Cloud Data Storage, using a tool for stream processing Dataflow
- Streaming data from IoT devices, apps, and services: Pub/Sub can consume, filter, and even store data that overburdens sensors, apps, and services until it is then sent to databases or other Google systems through Dataflow pipeline.
- Data replication from GCP databases: the distribution of change events gathered from different data storages allows analyzing their current state.
- Parallel processing of tasks and workflows using Pub/Sub messaging engine and CloudFunctions connection
- Distributing real-time data through enterprise event bus to prompt rapid real-time data processing
Dataflow
In a complex big data platform ecosystem, Dataflow stands as an essential component for ETL, batch and stream data processing and can flawlessly integrate with the other GCP tools described above. Leveraging Apache Beam’s open-source programming model for defining batch and streaming data pipelines, Dataflow can rapidly build data pipelines, oversee their execution, transform, and analyze data.
As another fully-managed service, Dataflow automates the provisioning and management of resources required for data processing. And coupled with autoscaling of resources, the tool presents the necessary capacity for dealing with spikes in workloads, thus providing resource and costs optimization. It’s also worth mentioning that Dataflow ensures the parallel processing of large datasets, which makes its high performance invaluable for a big data platform.
To see how all these tools can be matched together in a powerful data platform, let’s consider one of our client’s real-world use case.
Building a Data Platform on Google Cloud for the International Media Company
What the Client Expected
A media giant, an entertainment company with over 50 TV channels and different types of digital content created, came to Infopulse with the need to optimize large volumes of their media content and enable its quick processing in the cloud. However, since the client had some security concerns, the high-resolution media files and other important files had to be stored on-premises. Thus, we had to build a hybrid infrastructure that would fit in with the Google Cloud Platform infrastructure and meet industry-specific requirements. Besides, the client wanted to develop an intuitive recommendation engine leveraging machine learning capabilities.

What Infopulse Achieved
With the advantage of large expertise in the implementation of Google Cloud services and advanced data analytics services empowered with AI, Infopulse offered the client to build their data platform on GCP as it is fully managed and offers unmatched performance and flexibility in resource management and cost optimization. The chosen tech stack was also more suited to the needs of the client as GCP facilitates the usage of machine learning algorithms for building a recommendation engine for users.
Considering the hybrid nature of the platform, Infopulse built a system for collecting the metadata (e.g., a movie scene description, movie frames, technical parameters, film content, etc.) needed for a quick information search in tons of available media files. To rapidly extract such metadata, our team developed Machine Learning scripts using Google Cloud ML capabilities. For analyzing massive amounts of video files, we used on-premises GPU as it was more cost-effective as compared to large-scale video analysis in the cloud.
To store all the types of metadata as well as low-resolution videos and films with watermarks, the team chose Cloud Storage as it offered the necessary level of flexibility, scalability, and resource optimization. Another storage we used was BigQuery as a relational SQL-based DWH for keeping the structured data related to more general metadata of the motion picture (release date, director, genre, etc.). Another database that supported the client’s big data platform was Bigtable as a distributed NoSQL database for storying petabyte-scale structured data. At the same time, high-resolution media files and almost all the films of a broadcaster were still housed on-premises considering the client’s security and data privacy requirements.
The Media Data Platform Architecture Leveraging Google Cloud
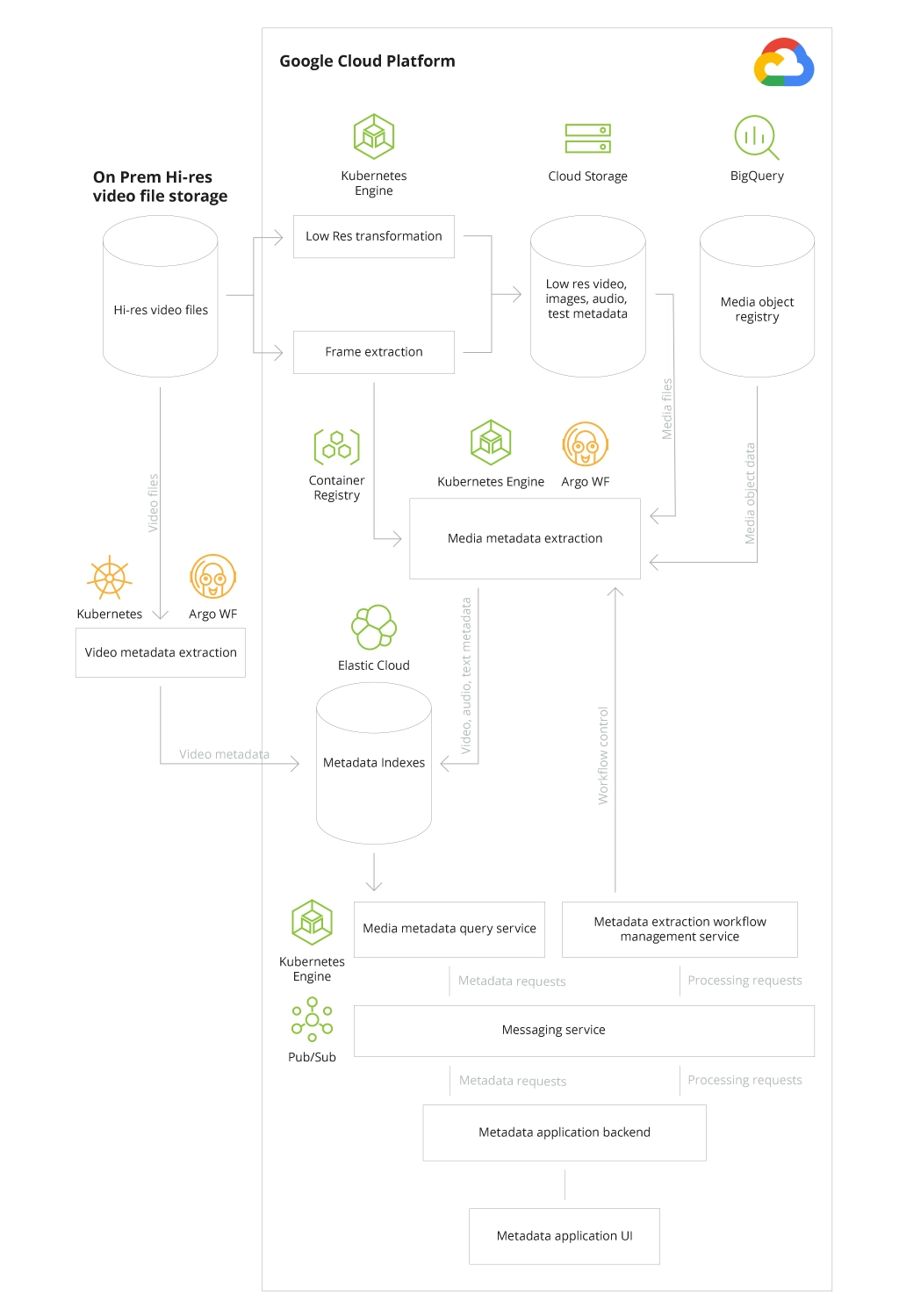
To ensure seamless integration and fast messaging-oriented communication between these cloud and on-premises services, our team chose Pub/Sub middleware that allowed to overcome a number of issues offering the highest throughput. Infopulse also set up an indexing system based on the Google’s partner solution Elastic Cloud Search smoothly integrated in the GCP ecosystem to enable fast metadata search based on their attributes. All this helped the client to build a recommendation engine for customers that could analyze metadata, as well as the viewers’ tastes and preferences and provide them with more relevant suggestions.
The metadata processing was performed using microservices architecture powered by Google Kubernetes Engine (GKE) which greatly simplified the development and deployment processes. Machine Learning scripts were packaged in Docker containers, and to run them sequentially or in parallel Argo Workflow was applied on top of the GKE.
What Was the Value for Business
Overall, the client received a highly scalable, flexible, and high-performing data platform for storing and analyzing their massive volumes of media data. Balancing the odds of the hybrid infrastructure, Infopulse also implemented Machine Learning algorithms so that the broadcaster could provide its customers with effective and accurate recommendations. The latter results in elevated customer engagement and retention. Moreover, relying on Google Cloud Platform’s big data capabilities, Infopulse helped the client to optimize costs, manage expenses, and simplify the administration and management of underlying infrastructure and capacity.
Closing Points
Setting up and managing a data platform on the Google Cloud Platform presents numerous benefits to businesses that have a strong big data analytics strategy in mind. To name a few, GCP has highly efficient serverless microservices architecture, a greater choice of storage, compute, and AI solutions for different use cases, fully managed cloud infrastructure, automated resource allocation, and greater costs optimization needed for DevOps and administration-related tasks. However, to make the most of these and not fall short due to the lack of expertise in Google Cloud solutions, you will most likely need the help of a proficient IT services provider.

![Carbon Management Challenges and Solutions [thumbnail]](/uploads/media/thumbnail-280x222-carbon-management-3-challenges-and-solutions-to-prepare-for-a-sustainable-future.webp)

![Automated Machine Data Collection for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-how-to-set-up-automated-machine-data-collection-for-manufacturing.webp)


![Pros and Cons of CEA [thumbnail]](/uploads/media/thumbnail-280x222-industrial-scale-of-controlled-agriEnvironment.webp)

![Data Analytics and AI Use Cases in Finance [Thumbnail]](/uploads/media/thumbnail-280x222-combining-data-analytics-and-ai-in-finance-benefits-and-use-cases.webp)
![Data Analytics Use Cases in Banking [thumbnail]](/uploads/media/thumbnail-280x222-data-platform-for-banking.webp)
![Digital Twins and AI in Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-digital-twins-and-ai-in-manufacturing-benefits-and-opportunities.webp)