![Big Data Platform on AWS [banner]](https://www.infopulse.com/uploads/media/banner-1920x528-aws-data-platform-20230227.webp)
AWS at Core: Ideal Suite of Solutions to Set up a Big Data Platform
On average, each organization that moves its core data and processes to the cloud faces some kind of turmoil: What vendor to settle on? Who provides the most cost-effective suite of services to handle massive volumes of data? How to ensure that technical teams and business users are completely satisfied with the choice? In our earlier posts, we already described what Microsoft Azure and Google Cloud Platform could do to match those exacting demands and standards.
Now, it is time to explore Amazon Web Services offerings in this vein. A true leader in providing highly scalable, durable, and efficient cloud infrastructure, AWS takes the largest market share — 34%, thus leading the Top 3 cloud infrastructure providers ranking by Synergy Research.
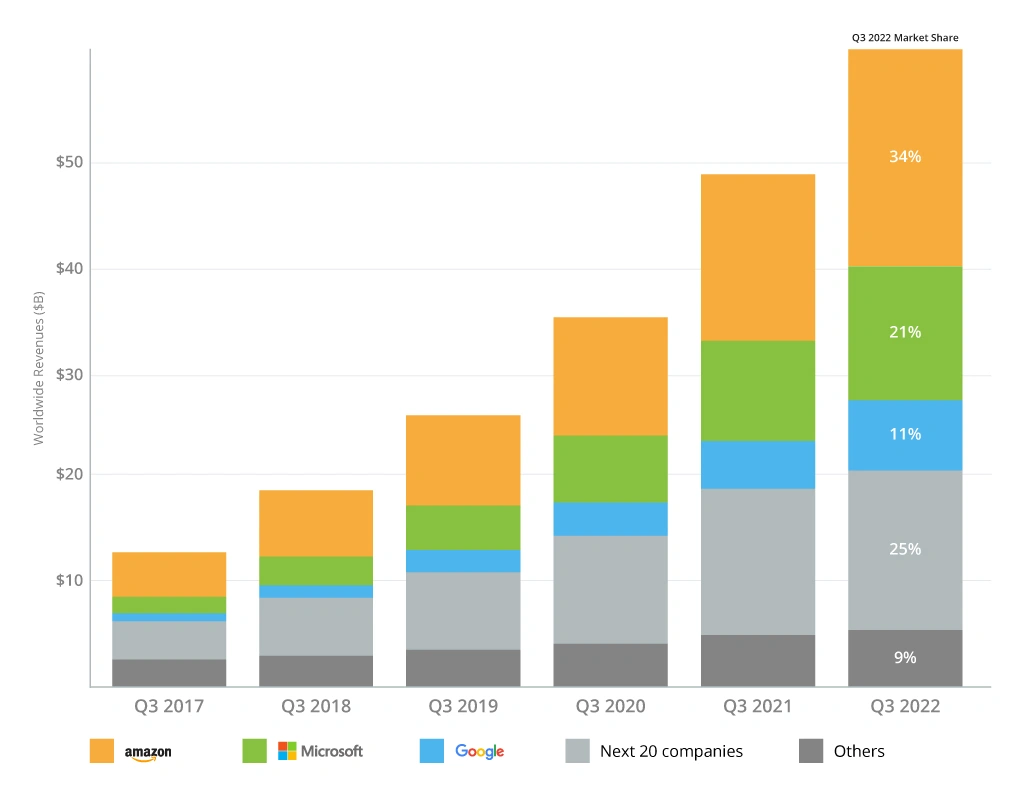
In this post, you will get an overall picture of AWS capabilities in big data, how well it caters to the needs of companies who operate with large, highly connected datasets and what thriving companies have chosen AWS to modernize their core solutions.
What You Should Know about AWS 3V Parameters
When building a big data platform on AWS, Infopulse recommends utilizing cloud-based solutions that can actually match the 3 V’s parameters of big data – volume, velocity, and variety. Let us compare how major data storage and analytics offerings like Amazon S3, Redshift, Neptune, Athena, and Aurora fully satisfy the requirements of big data processing.
Data Volume (amount of data) – in S3, the amount of stored data and objects is unlimited (yet the size of each object in a bucket cannot exceed 5 TB), while Redshift allots up to 16 petabytes and Aurora amounts to 128 terabytes.
Data Velocity (the speed of data generation and processing) – S3 allows 5500 requests per second by default (if needed, the number can be scaled to up to 55,000 read requests) and has the ability to scan millions of objects per one query; Amazon Neptune can deal with over 100,000 queries per second.
Data Variety (structured, semi-structured, unstructured datasets) – S3 is capable of storing any type of data coming from heterogeneous sources, while Amazon Athena supports the processing of all three types of datasets and different data formats (e.g., Apache ORC, JSON, CSV, Apache Avro, etc.), etc.
Now, let us look closer at the capabilities of the most requested AWS services for building a big data platform. Together they make a powerful ecosystem of services to enable high scalability, security, and automation of essential data storing and management solutions.
Amazon Web Services Toolkit for Setting up a Big Data Platform
A Sample of Architecture of a Big Data Platform on AWS
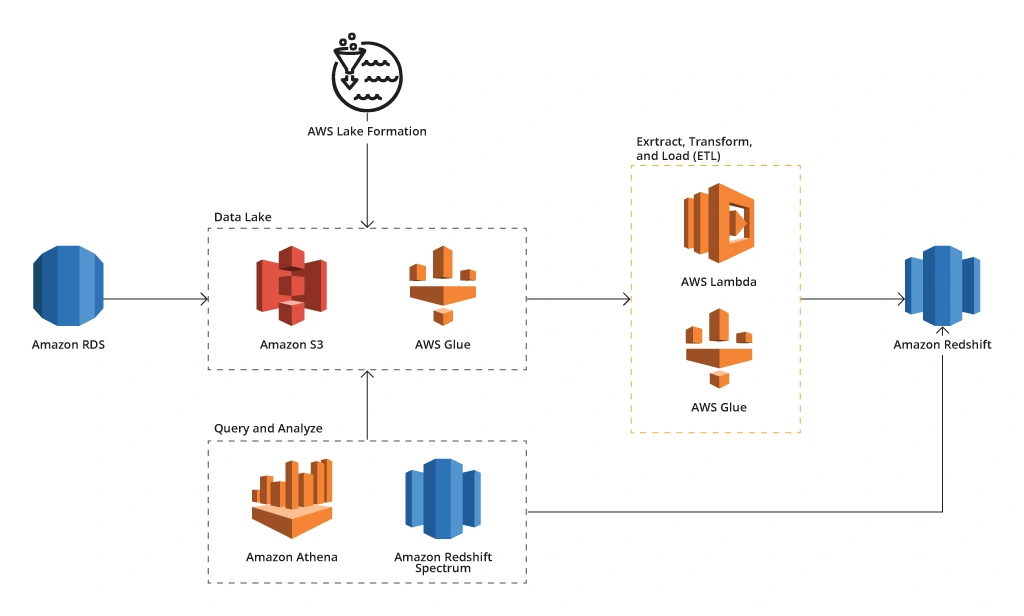
Amazon S3 (Simple Storage Service)
Any big data project with AWS at the core should rest on Amazon S3 as your main object storage that is especially useful when building a cloud-based data lake. In over 16 years of Amazon S3’s presence at the market, it has grown to over 100 trillion objects, hence you can imagine the scale of this limitless repository.
Time- and peak load tested through Amazon.com’s development path, S3 has evolved to a robust petabyte-scale file storage. Each object can contain up to 5 TB of data and is placed in a separate bucket. In those buckets you can keep literally any type of data – relational (structured), semi-structured, raw, unstructured, e.g., images, video files, in their original formats.
Data access is secured by default while the process of data retrieval and further analysis is simplified with easily integrated Amazon services, such as AWS Lambda, AWS Neptune, AWS Redshift, etc. Amazon S3 also fully meets reliability, performance, and business continuity requirements with its 99,9999999% durability and 99,99% data availability.
Having decoupled storage and compute power, S3 minimizes costs and the resources needed to run complex workloads while providing maximum flexibility and scalability since you can simply opt for the required storage resources independently from the compute capacity. Besides, the pay-as-you-go model of S3 and its storage classes built around frequency and immediacy of accessing the storage help gain from big data without punching a hole in your budget. By the way, the popular online marketplace Airbnb relied on S3 and its storage classes to reduce their data warehouse costs by almost 27%.
Amazon Athena vs. Amazon Aurora
Both services can be used to query large-scale data sets stored in Amazon S3, however, they act differently. Amazon Athena is primarily a serverless interactive SQL-based query service that ignores the need of a separate data warehouse and ETL. Instead of loading data from S3, Amazon Athena runs analytical queries directly in S3, which allows getting the results in a couple of seconds. The absence of a server helps skip infrastructure provisioning. Cost-efficiency can be also reached through paying only for the queries you actually run.
Amazon Aurora, a relational database with MySQL and PostgreSQL compatibility and autoscaling up to 128 TB, ensures the rapid and easy export-import of data to and from S3. If you settle on Aurora, as your big data database, then you may want to know that Aurora seamlessly integrates with such analytics systems as Amazon Redshift (by zero-ETL principle) and Amazon QuickSight. Moreover, Aurora’s compute power and high throughput allow for running analytical and transactional queries in parallel as well as ensure the topmost performance and scalability. Case in point, Atlassian used Amazon RDS together with Aurora PostgreSQL to scale up easily and host over 25 000 users for each tenant.
As to the cost reduction, the results of real-world implementations speak for themselves. Samsung, for instance, cut monthly operational costs by 44% when they moved their highly monolithic DWH to Amazon Aurora PostgreSQL.
Amazon Neptune
As a fully managed graph database capable of querying billions of relationships in just milliseconds of time, Amazon Neptune can become a valuable component of your AWS data platform. Neptune facilitates dealing with large, interrelated graph datasets. This database supports popular graph models and standard query languages like Gremlin, SPARQL, and openCypher.
In addition, Python integration, which prompts graph data analytics and running machine-learning algorithms, is also available. The latter may turn into a good springboard for such trendy use cases as building a recommendation engine, fraud detection, improved security management, predictive analytics, etc. Another feature resilient companies value a lot these days is Neptune’s fault-tolerance and self-repairing capabilities thanks to the support of almost 15 read replicas distributed across three Availability Zones. The latter also contributes to the 99.99% availability of Amazon Neptune.
Look further below to find a real-world case study of how Infopulse built a data platform for the large audit and consulting company utilizing Amazon S3 and Amazon Neptune among others.
Amazon Redshift
As part of the analytics layer, this fully managed cloud data warehouse with columnar storage type greatly optimizes data retrieval and analytical querying. Since the speed in big data processing wins the day, Redshift is equipped with massive parallel processing and the ability to handle petabyte-scale data sets gathered from a variety of sources. Amazon Redshift allows collecting and analyzing only structured or semistructured data to help data analysts and business users derive more valuable insights. However, there is a way to tap into the potential of unstructured data by integrating Redshift with S3.
As well as other Amazon’s repository offerings, Redshift also automates infrastructure provisioning and administrative tasks, such as backups, replication, monitoring, etc.
A case in point: Nasdaq, an international financial and technology corporation, used Amazon S3 and Amazon Redshift to provide the needed scalability and flexibility of their data lake solution when ingesting up to 113 million records a day.
Another valuable feature Redshift entails is building machine-learning models. Redshift acts in tandem with Amazon SageMaker, a comprehensive service for training an ML model. With data from Redshift you can use simple ML models, deploy trained models with SageMaker automatically, and create a prediction. In this case, the ML model can be easily applied to data and integrated into queries, dashboards, and reports to simplify predictive analytics for multiple use cases, e.g., sales and equipment/systems maintenance predictions, risk scoring, fraud detection, churn prediction, etc.
AWS Glue
AWS Glue is an advanced ETL service that simplifies data discovery, preparation, and movement from over 70+ heterogeneous data sources. AWS Glue is closely connected to its core component Data Catalogue that stores metadata sources and targets. To shift such data from a source to a target, AWS Glue performs jobs set to run ETL scripts using either Apache Spark for processing data in batches or data streams or Python environment (specifically Python shell jobs to extract source data outside AWS). Overall, AWS Glue ensures robust ETL processes and seamless data integration utilizing automatic data classification, categorization, cleaning, transformation, and trusted transfer.
AWS Lambda
This serverless compute service functions as a trigger for over 200 AWS services and allows the system to run a code for different apps and backend services with no need to provision and manage servers.
AWS Lake Formation
Building a data lake with AWS Lake Formation can take a few days, thus simplifying and accelerating many labor-intensive and time-consuming data management operations. Also, by centrally governing data from all the available sources, AWS Lake Formation takes a crucial role in the metadata and data access control, enabling their security and reliability.
Real-World Use Case: A Big Data Platform on AWS for 100,000+ Users
What the client needed
Our client, a large audit and consulting company, provides professional services (audit, tax, consulting) to various companies around the globe. The client had an extensive network of different contacts and their interactions within and outside each company. The data on such contacts resided in heterogeneous systems and most often lacked consistency. To gather all the contacts in one place and map all their relationships, the audit company decided to build a single data platform unifying such data and allowing users to simply acess and act upon it. The client engaged Infopulse as its long-term partner and experienced deliverer of complex data analytics projects.
What solution Infopulse offered
Infopulse built a big data platform powered by AWS analytics services to enable robust data aggregation – over 100 million records, including both financial and contact data from diverse sources. The data sources presented different systems that required additional manual processing to identify data conflicts, duplicates, inconsistencies, or any errors that impeded flawless data analysis. Overall, Infopulse developed and successfully implemented an elaborate architecture of the solution:
Architecture of AWS Big Data Platform
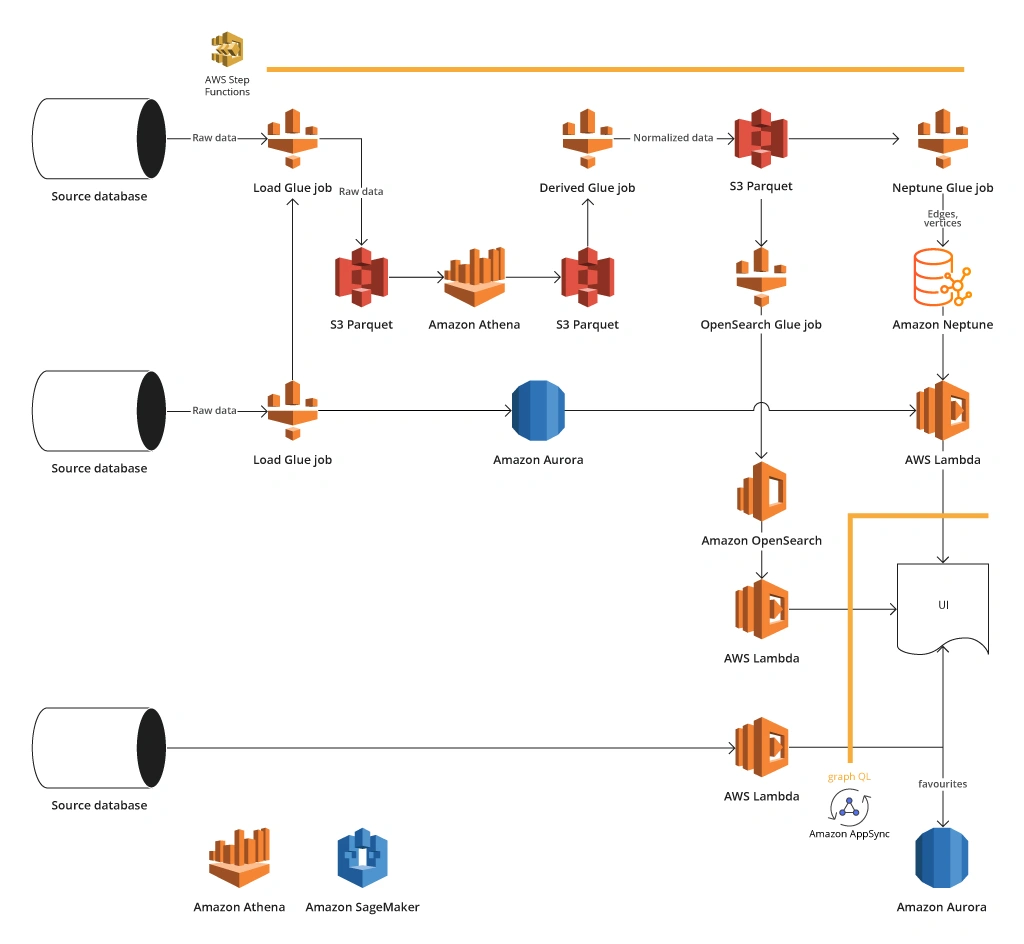
- Ensured data unification to remove duplicates and improve data accuracy
- Enabled contact data analysis related to customers’ personnel and their interactions with other departments and executives
- Retrieved data from heterogeneous systems using APIs, files replication, direct access to databases of systems, etc.
- Stored large volumes of intermediate data using an object repository Amazon S3 that also served as a data lake with its boundless scalability and high resilience
- Used Amazon Neptune, a graph oriented database, for storing critical contact and financial data of companies the client dealt with. Neptune fit well to build a network of customers (employees, managers, etc.) and their relationships considering different parties involved. However, to facilitate data analysis of interactions, the team also applied Amazon Athena and then incorporated Aurora as an RDS database, which allowed storing large volumes of data and accelerated interactions processing
- Ensured data transformation with AWS Glue jobs
- To enable quick data search by different attributes (be that email, alias, or contact data), the team set up Amazon OpenSearch
What value the client gets
- Consolidation of all data about the client’s customers and their employees created a golden record and a single source of truth
- Enhanced data quality, its completeness, consistency, accuracy, and reliability
- Facilitated the access to data for over 100 000 business users of an audit company (even if records are simultaneously requested), which also improves data analytics and insights-driven decision-making
- Simplified discovery of relationships and interactions between different contacts of companies who used or still use services of the audit firm. All this greatly improves communication and collaboration of business users.
- Automated data processing that prompts faster data analysis and related data management activities.
Wondering whether this solution could also help your company build an effective data storage and analytics solution? Infopulse’s cross-industry experience allows applying profound expertise in AWS solutions to almost any possible use case. If you are open to discuss your potential benefits from AWS, let us start with small talk.
Closing Points
Modernizing your data storage and business analytics solutions, you should decide on the most optimal suite of tools to ensure effective data collection, ETL processes, data analysis, visualization, and reporting. The capabilities of AWS seem unlimited and alluring for big data analysis. However, to get the most merits, you should have enough expertise to understand what database or data processing solution can match to your specific use case. Infopulse can help you with this, offering professional AWS and data analytics services.

![Generative AI and Power BI [thumbnail]](/uploads/media/thumbnail-280x222-generative-AI-and-Power-BI-a-powerful.webp)
![Data Governance in Healthcare [thumbnail]](/uploads/media/blog-post-data-governance-in-healthcare_280x222.webp)
![AI for Risk Assessment in Insurance [thumbnail]](/uploads/media/aI-enabled-risk-assessment_280x222.webp)
![IoT Energy Management Solutions [thumbnail]](/uploads/media/thumbnail-280x222-iot-energy-management-benefits-use-сases-and-сhallenges.webp)

![Carbon Management Challenges and Solutions [thumbnail]](/uploads/media/thumbnail-280x222-carbon-management-3-challenges-and-solutions-to-prepare-for-a-sustainable-future.webp)

![Automated Machine Data Collection for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-how-to-set-up-automated-machine-data-collection-for-manufacturing.webp)

