![Cloud Data Platforms [banner]](https://www.infopulse.com/uploads/media/the-many-faces-of-cloud-cata-platforms-1920x528.webp)
The Many Faces of Cloud Data Platforms: Data Warehouse, Data Lake, and Data Fabric
If your organization is looking into ways of improving the cost, efficiency, and value-generation potential of big data, you have likely considered different cloud data storage platforms and data management architectures. However, the pressing question is, which approach should you go for? We attempt to provide a detailed answer in this post.
The Three Types of Cloud Data Storage Solutions
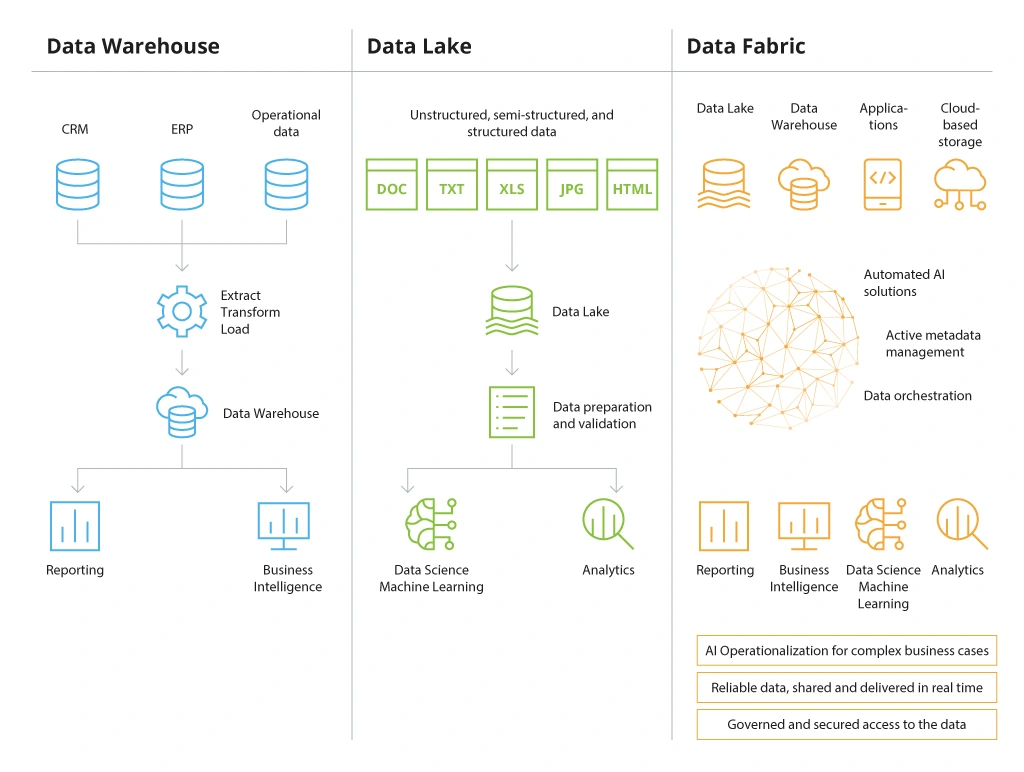
The universe of cloud data storage services can be hard to navigate. Below is a recap of the three main approaches to designing your cloud-based data storage architecture.
What is a Data Warehouse?
Data warehouse (DW) is a system for aggregating data from connected databases – and then transforming and storing it in an analytics-ready state. The main benefits of a data warehouse are effective data consolidation, fast pre-processing, and easy self-access for business users. The key constraint of using a data warehouse solution is the need to pre-transform all data using standard schemas. This increases the usage costs and reduces scalability potential.
Data warehouse solutions:
- Azure Synapse Analytics
- Amazon Redshift
- Google BigQuery
What is a Data Lake?
A data lake is a centralized cloud-based repository for storing raw (unprocessed, non-cataloged, or pre-cleansed) data from various systems. Unlike DWHs, data lake technology allows storing both structured and unstructured data of any size (as object blobs or files). Cloud data lakes are also more scalable and support more querying methods for data retrieval and analysis – a factor data scientists well appreciate.
Data lake solutions:
- Azure Data Lake
- Amazon S3
- Apache Hadoop

What is Data Fabric?
Data fabric is a collection of practices and tools used to implement data connectivity across the entire company estate – on-premises systems, all cloud data storage services, hybrid storage systems, and even edge devices. Think of a data fabric solution as the nervous system in our bodies. Its purpose is to distribute various kinds of information to the organs (business systems), requiring it for decision-making.
Data fabric is a complementary “coating” you can use to connect disparate data lake solutions with data warehouse tools to resolve interoperability issues, improve data distribution speed, and achieve better data standardization.
Data fabric solutions:
- SAP Data Intelligence
- IBM Data Fabric
- Google Cloud Dataplex
Learn more about data fabric use case scenarios from our previous post.
Main Considerations for Designing Cloud Data Platform Architecture
Given the wide range of choices, it is challenging to decide which cloud data storage solutions will best meet your company’s needs.
Data fabric might sound like the most “mature” choice, but this technology already requires a strong data governance framework – the one that your company may lack at this stage. Data fabric also does not assume permanent data movement. The data remains stored in the same target destination – be it a local database or cloud repository. Such solutions only enable better and faster data provisioning. Therefore, you still need to decide separately on the storage types, as well as your strategy for data virtualization.
Sample architecture for enterprise data management platform
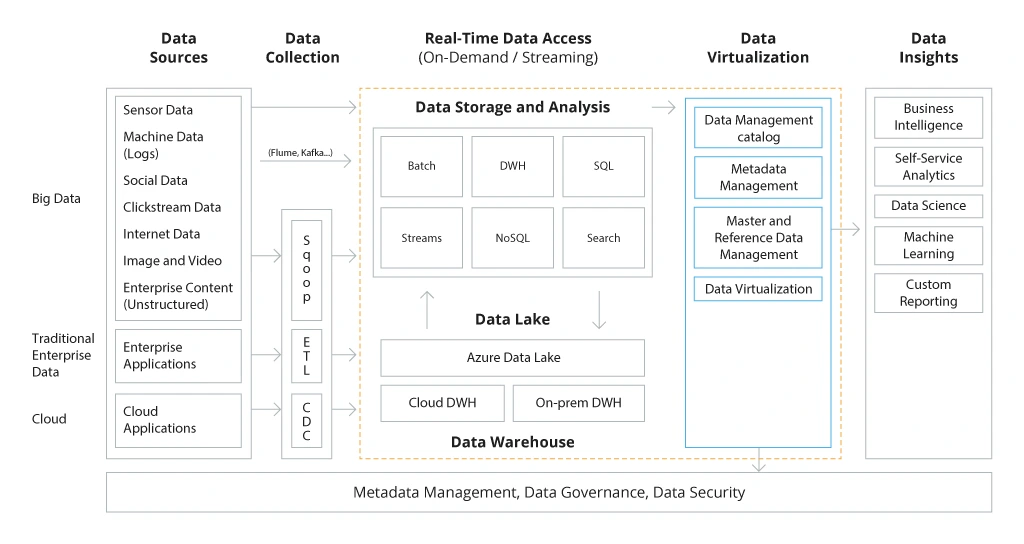
Both data warehouses and data lakes help you move necessary data from one place – your CRM system – to a new location (cloud DWH) – then prepare it for subsequent analytics.
Therefore, if you plan to explore a new big data analytics use case, adopt more self-service business intelligence tools (BI), or explore complex data science projects, you first need to decide on whether a data warehouse or data lake would serve as a better destination for a target data storage. Only afterwards, can you consider how to improve your data management with data fabric.
To help you with that, we have prepared a detailed comparison table, explaining the main difference between data lake and data warehouse.
Data Warehouse
Data Lake
Types of supported data
Primarily relational-data + custom built-in data types.
All data has to be pre-transformed to fit the supported data parameters and properly categorized.
Raw data in any format.
There are no limits on data format or size, nor any rigid requirements for data pre-cleansing.
Data storage format
Structured, pre-processed data, stored in an analytics-ready state for easy retrieval.
A combination of structured, semi-structured, or unstructured data is available for flexible querying.
Data processing
ELT (extract, load transform) on write.
OLAP(Online Analytical Processing).
ELT (extract, load transform) on read.
OLTP (Online Transaction Processing).
Data accessibility
Fast, using convenient interfaces.
Extra processing time is required for new data transformation.
Instant and on-demand, but often requires custom data querying.
Data exploration is possible immediately after ingestion.
Storage capacity
Moderate. Cloud-based DWHs can be easily scaled, but the data storage costs are higher compared to data lakes. Since many DWHs are SQL-based, there are also several inherent database scalability issues. You can mostly scale up or down.
High. Lower storage costs make data lake solutions a more attractive long-term data storage option. Can be easily scaled out on-demand by provisioning extra cloud resources.
Analytics capabilities
Well-suited for drill through or operations on rows, complex SQL queries.
Seamless integration with self-service BI tools, analytics services, and reporting apps.
Can be also used for data science projects if sufficient data sets are available.
Well-suited for processing column-oriented queries, as well as custom data sampling.
Provide ad hoc access to data samples of various big data analytics, machine learning, and deep learning projects.
Main users
Business users
Data scientists and engineers
Recommended use cases
Recurring business reporting
Self-service analytics
Data refreshers
Simple data science projects
Big data analytics
Machine learning / deep learning model training
Custom and one-time reporting
Ultimately when deciding on the shape of your cloud data systems, you need to consider subsequent data use cases above all else.
If you want to improve your business intelligence, streamline data analysis, and report generation, data warehouse tools can empower your operational teams with the need capabilities.
Proven data warehouse use cases include:
- Tactical and operational reporting
- Streamlined audit and compliance
- Data mining analytics
- Financial reporting
- Workplace analytics and reporting
You can learn more about the advantages of implementing a cloud-based data warehouse solution from our customer case study. With a new Azure DWH architecture, a team of 200 can now access and analyze data from over 20 sources at warp speed.
If you are interested in infusing data analytics into new customer-facing products, training complex ML/DL models, and running predictive analytics projects, a data lake solution may be better suited.
In this case, you forgo easy and fast querying in favor of unconstrained querying and custom dataset generations. Data lake analytics solutions can draw from a larger pool of sample data and transform it into new insights.
Common data lake use cases include:
- Company-wide decision intelligence engines
- Computer vision algorithm training
- Fraud detection and prevention
- Price forecasting and predictive purchase planning
- Real-time anomaly detection in data sets
Finally, it does not always have to be a data warehouse vs data lake choice – you can (and often should) incorporate both types of cloud data storage. Then "reserve" each option for different types of use cases – self-service access vs data science use cases. Data lakes allow you to parse through larger volumes of data and discover extra intel you can then segregate and send over to a DWH and vice versa.
That is when data fabric comes into play as a means to improve your data discovery and integration. Data fabric solutions help harmonize data exchanges between the different elements of your platform, ensure that all available data is properly categorized, and processed in line with compliance requirements. At the same time, data fabric can also be programmed to look for extra data to add to a lake or a warehouse for specific query processing.
Common data fabric use cases include:
- Data management process consolidation and automation
- Enhanced data discovery for ML/DL projects
- 360-degree data collection for various use cases
- Progressive data consolidation and de-silos
- Data marketplace development (as an external offering)
Checklist for Selecting the Optimal Cloud Data Platform Architecture for Your Business
- Where is your data stored? Map all the data sources you would want to connect for better reporting. Then analyze if you can enable access through a virtualized layer (pre-made connectors, APIs, or custom data integration pipelines) or need to copy the data into a single system.
- What are your data formats? For each source, determine whether the stored data is structured (stored in relational databases) or unstructured (hosted in non-relational databases). A data lake can accommodate both formats, whereas moving non-relational data to a DWH will require extra transformations, more time and costs.
- What are your main use cases? As mentioned earlier, DWHs and data lakes are inherently better suited for respective analytics use cases. Thus, collecting feedback from different users – line of business leaders and data engineering team – will help to understand their scope of needs and current limitations.
- Do you have full visibility into your data? To prevent irrelevant and invalid insights from cluttering your data storage systems, you need to implement a set of controls for data mapping, discovery, validation, and metadata management. This is what data fabric is meant to do.
- Are there any compliance requirements? Regulators prohibit businesses from processing sensitive customer data such as personal identifiable information (PII). Therefore, you must ensure that any data that goes into your cloud storage is scrubbed clean from such insights or properly anonymized. Onward, data fabric solutions can be programmed to automatically check all processed data against codified compliance requirements.
- How do you plan to ingest data? For each use case, you need to determine whether new data ingestions will happen at a regular cadence (e.g., weekly) or dynamically (as soon as new insights become available). DWHs and data lakes can both handle concurrent workflows, but DWH solutions require more time for data processing.
- How do you plan to secure your data access? In each case, you will need to implement access management policies for accessing different types of insights. Additionally, you will have to secure all data exchanges, enable data encryption (where necessary) and implement protection policies for data at rest.
To enable effective data processing in the cloud, you will need to design the optimal approach to retrieve, move, store, and operationalize data across an array of systems, documented in your data governance strategy. Based on it, you can then select the best type of data cloud storage to fulfill specific use cases, and then converge them into a more complex data platform architecture, governed by data fabric.

![Generative AI and Power BI [thumbnail]](/uploads/media/thumbnail-280x222-generative-AI-and-Power-BI-a-powerful.webp)
![Data Governance in Healthcare [thumbnail]](/uploads/media/blog-post-data-governance-in-healthcare_280x222.webp)
![AI for Risk Assessment in Insurance [thumbnail]](/uploads/media/aI-enabled-risk-assessment_280x222.webp)
![IoT Energy Management Solutions [thumbnail]](/uploads/media/thumbnail-280x222-iot-energy-management-benefits-use-сases-and-сhallenges.webp)

![Carbon Management Challenges and Solutions [thumbnail]](/uploads/media/thumbnail-280x222-carbon-management-3-challenges-and-solutions-to-prepare-for-a-sustainable-future.webp)

![Automated Machine Data Collection for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-how-to-set-up-automated-machine-data-collection-for-manufacturing.webp)

