
6 DevOps Best Practices to Launch Enterprise-Wide Transformations
Enterprises can no longer afford to ignore the rapid changes in the ways how software is shipped. DevOps has emerged as movement to address the pressing shortcomings of the product development lifecycles – extended deployments, ineffective testing, siloed communications and teams being stuck with performing mundane, rather than doing high-value work.
In the previous post, we have already explained the exact business value of DevOps and the key principles it should be based upon. The principles mentioned in the previous sections should be backed by respective practices, promoting faster software development; increased code quality; active knowledge exchanges and collaboration.
DevOps is an organization-wide culture and it must be continuously nurtured by introducing respective best practices.
1. Continuous Delivery
Continuous delivery is a software development practice that enables product owners to ship product changes at any stage without hampering the product performance, quality or user experience.
All the new code changes are built, tested and prepared for a release automatically to the production-like environment from system/application configuration stored in the version control. Deployment to production can occur manually or automatically depending on the business needs.
Continuous delivery enables businesses to release new features; fix bugs or make any server-side configuration changes in the background without compromising the product’s performance.
The goal of continuous delivery is to have the code available in a deployable state at any given timeframe. The project itself may be half-boiled, but the proposed new features are already vetted, tested, debugged and ready for deployment whenever needed.
At Infopulse, the continuous delivery framework operates in the following manner:
- Core tasks are broken down into small-size updates by the developers. Originally made in version control, those updates will be deployed to production-like environment once complete.
- After the new code is committed, the team receives instant feedback from a series of automated test cases (acceptance testing, performance testing, regression testing, security testing etc.) deployed by respective tools.
- If an automated test fails for some reason, the responsible developer will manually look into the case and make fixes.
- Additional automated testing may be triggered if needed before the final feature release.
The baseline principle of continuous delivery is that development and testing are merged into one unified process. It is organically integrated into the delivery workflow and speeds up the product timeline while ensuring that quality standards are met.
Continuous delivery practice is often associated with continuous deployment. The latter is a separate process that may (or may not) be part of your workflow. Continuous deployment assumes that every product change or update is deployed automatically to production without any manual supervision from a DevOps engineer.
Continuous delivery practice does not incorporate automated deployment. There is a technological capacity to deploy new changes automatically, but the deployment can be scheduled manually for respective business reasons.
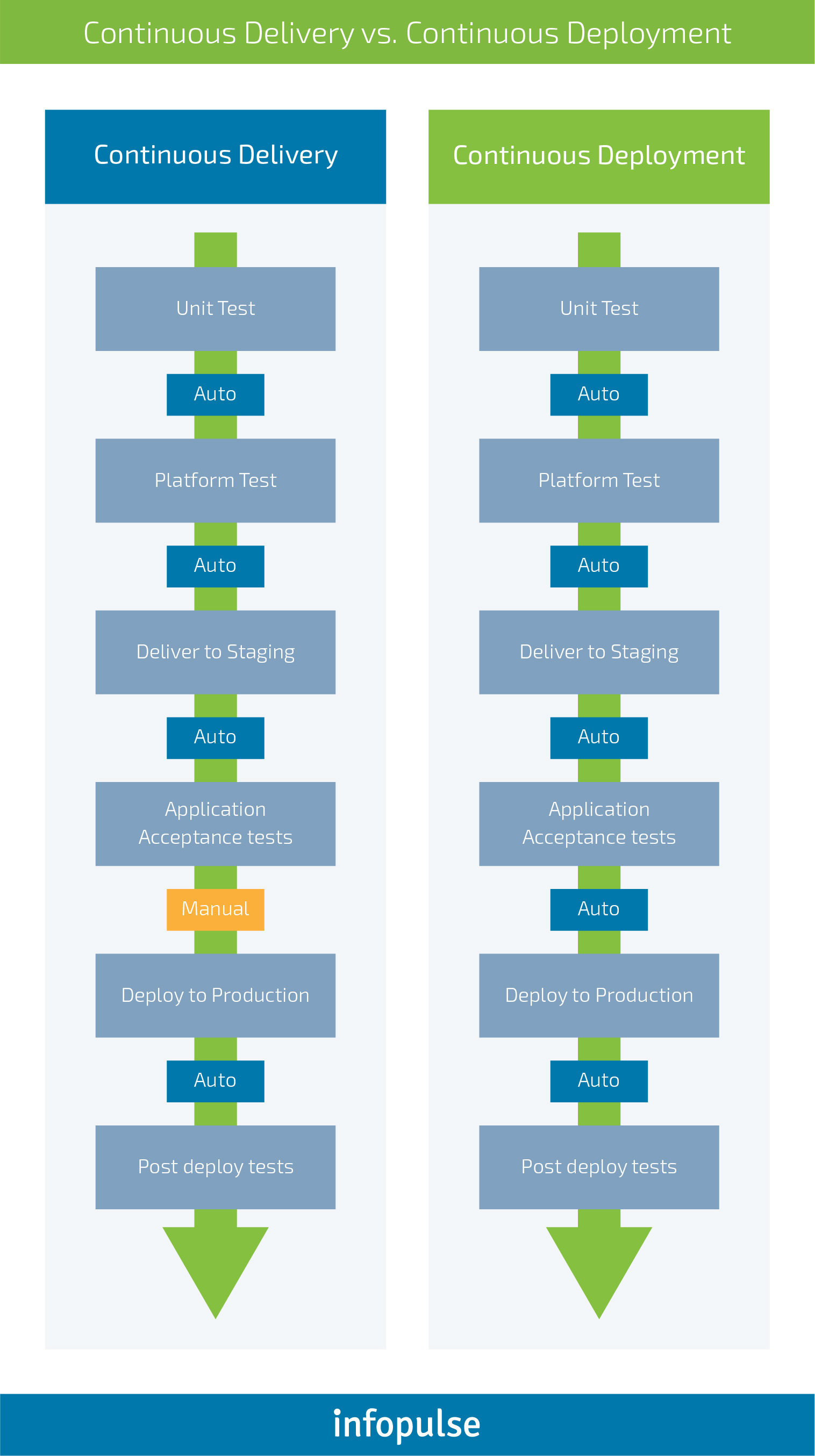
Continuous integration is another optional practice of the continuous delivery framework. It assumes that all developers submit code to one central branch of the repository multiple times per day. The goal here is to maintain the most current version of the source code in one place so that each team member could review or pull from the latest code version to avoid any potential conflicts. Continuous integration reduces the time required to validate new updates; improves the software/code quality and helps locate and address bugs faster.
2. Microservices Architecture
A single application is no longer viewed as a monolith one. Microservices architecture practice breaks down the entire product into a set of small services and features. The design architecture is developed in a way that allows each service to run its own processes and interact with other services using lightweight mechanisms such as APIs (application programming interfaces).
The main idea is to decompose a large product into individual services that are tied to a single purpose. This way your product becomes more modular – each service can be understood, developed and tested independently without compromising the entire product. The overall architecture becomes resilient to erosion over time.
The key principles of microservices architecture are as follows:
- Each service is independently deployable; decentralized; built and released using automatic tools and processes.
- Services (or groups of services) are easy to replace or revoke if needed.
- Services can be developed using different programming languages, databases, software and hardware environments depending on your current business needs.
- Services are grouped around certain use cases e.g. billing, front-end, logistics etc.
A microservices-based architecture enables better agility and allows businesses to scale their product effortlessly at a lower cost and within a shorter time frame. As part of the continuous delivery framework, the microservice architecture allows to deploy application changes by re-building and re-deploying only one or a limited number of services.
3. Communication and Collaboration
DevOps culture bridges the divide between different teams through increased collaboration, transparency and knowledge exchange. The layering principle is that the same people who develop an application should be involved in shipping and running it.
Extensive usage of respective tools and automated delivery processes already encourage tighter cooperation between the two different entities (developers and operations). Merging workflows and operations should not be the final point though.
DevOps culture is based on the pillars of sharing and active knowledge exchange. As the Third Way principle states – empower your teams with the right tools for continuous experimentation and lifelong learning. Strive to build an environment that maximizes knowledge sharing and encourages communication across different teams – developers, operations, marketing, sales, and even customer support. Every person in your organization should understand the overall business goals and align them with their project and task at hand.
Work towards creating and maintaining corporate wikis that would detail all product aspects and continuously communicate the current best practices, product values and project goals. Create documents that outline:
- Information Architecture: all user interfaces, wireframes, mockups and other UX materials.
- Design Specifications: brand colours, fonts, required dimensions, aesthetic factors and so on. Be as specific as you can.
- Product Description: key product features and requirements; overall product business logic and suggestions about the future features.
- Development Handbook includes information about all the key technology you are using, current architecture, quality assurance guidelines, key tools, overall software development lifecycle (SDLC).
If you are managing a distributed team or outsourcing part of your operations, leverage the next practices to boost knowledge exchange between in-house and remote personnel:
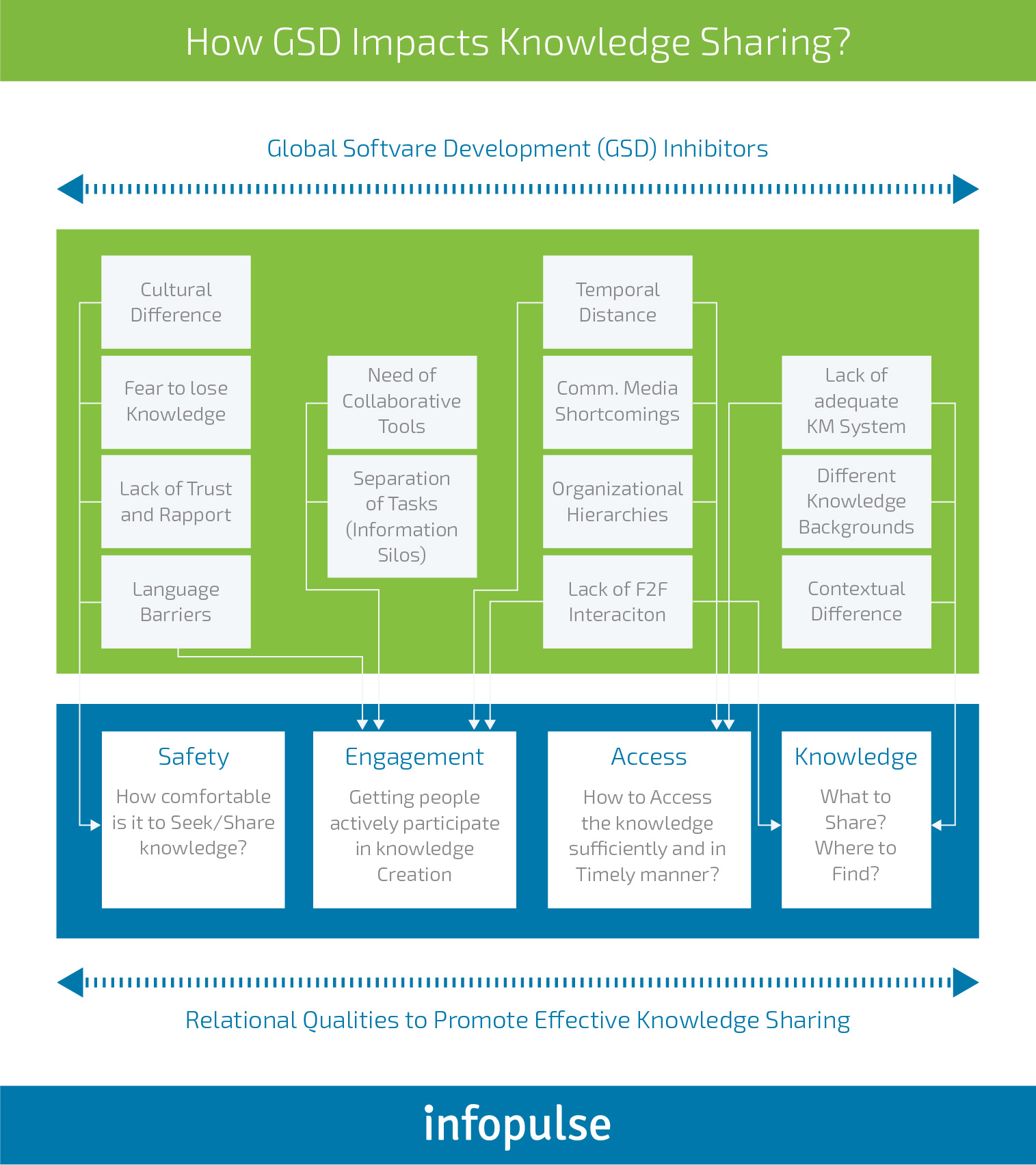
Make it easy for everyone on the team to know what is happening at any given time.
4. Automated Infrastructure
Infrastructure as Code (IaC) practice assumes that every step of infrastructure creation (including server propagation, OS installation/configuration etc.) can be performed with respective scripts. Infrastructure is provisioned and managed using code and with the help of version control and continuous delivery techniques.
Infrastructure coordination should not be tied to a single machine or cluster but can be copied and replicated for as many nodes as needed. Different team members can alter and improve the configurations through the development lifecycle using standardized patterns.
Popular DevOps tools like Puppet and Chef can help you orchestrate and fine-tune your setup by automatically generating necessary scripts to support the Infrastructure as Code workflows.
System administrators can further use code to automate operating system and host configuration, standard operational tasks and additional common processes. This reduces the number of manual operations the staff has to perform, freeing their time for more valuable tasks.
5. Chaos Engineering
The main idea of chaos engineering is that modern distributed software applications must be prone to experiencing unexpected turbulent conditions. Thus, such systems must be initially designed to resist unexpected problem and weaknesses in production environments.
Chaos engineering is based on four key principles that development teams use for probing software system weaknesses:
- Define a steady state – a certain measurable output of your system that stands for normal behavior.
- Assume that this steady state will remain as it is both in the control group and the experimental group.
- Add variables that will represent real-world events such as server outages or crashes, hard drive malfunctioning, network connection problems and so on.
- Attempt to disprove the initial hypothesis by searching for a difference in steady state between the control group and the experimental group.
Encourage your team to experiment with random failure of non-critical services and system cases. The development team should be tasked with creating fast, automated responses for such cases, gradually moving on from the non-critical services to the critical services and a combo of different failures.
The goal of chaos engineering is simple – train your teams to build architecture and systems that can automatically adapt to failures, without hampering the core functionality of the software.
Netflix is identified as the pioneer of chaos engineering. The company started migrating their data centers to the cloud in 2008 and incorporated some degree of resiliency testing in production. Later, their in-house experiments grew into an open-source Chaos Monkey project – a tool that randomly selects groups of systems (services) and terminates one of the systems in that group. The “failure” is staged at controlled time and interval so that there is staff around to investigate the problem and the system performance.
By adding an element of failure to the mix, the Netflix team encouraged developers to create systems that could function autonomously in case of failure and create resilient design architecture from day one.
While chaos engineering is a trailblazing practice that allows creating robust systems, prone to many types of failures, the practice may not be suitable for organizations at early stages of DevOps adoption.
6. Transformational Leadership
DevOps fosters extensive organization-wide transformation that goes beyond the development and Ops teams. IT leadership will also need a major overhaul. By 2020, it is predicted that 50% of CIOs who have not transformed their capabilities will be removed from the digital leadership team.
Winning teams should be led by engaged and transformational leaders – the ones capable to inspire and motivate others to do their best work through appealing to their core values and sense of purpose. Transformational leaders should occupy both mid-level and senior positions to encourage wide-scale organizational change. Their main goal is to get their teams to identify with the organization/project they are working for and support the organization’s main business goals and objectives.
Other DevOps practices will fall flat in the long run without the active and constant support of the new leaders.
Infopulse team would be delighted to assist you with your transformation. Our DevOps Consultants can help you with implementing DevOps from the ground or adapt and manage ongoing projects in line with the DevOps best practices, provide extensive training to your staff and help your company gain a new competitive edge.
![Power Apps Licensing Guide [thumbnail]](/uploads/media/thumbnail-280x222-power-apps-licensing-guide.webp)
![How to Build Enterprise Software Systems [thumbnail]](/uploads/media/thumbnail-280x222-how-to-build-enterprise-software-systems.webp)
![Super Apps Review [thumbnail]](/uploads/media/thumbnail-280x222-introducing-Super-App-a-Better-Approach-to-All-in-One-Experience.webp)
![ServiceNow and Third-Party Integrations [thumbnail]](/uploads/media/thumbnail-280x222-how-to-integrate-service-now-and-third-party-systems.webp)
![Cloud Native vs. Cloud Agnostic [thumbnail]](/uploads/media/thumbnail-280x222-cloud-agnostic-vs-cloud-native-architecture-which-approach-to-choose.webp)
![DevOps Adoption Challenges [thumbnail]](/uploads/media/thumbnail-280x222-7-devops-challenges-for-efficient-adoption.webp)
![White-label Mobile Banking App [Thumbnail]](/uploads/media/thumbnail-280x222-white-label-mobile-banking-application.webp)

![Mortgages Module Flexcube [Thumbnail]](/uploads/media/thumbnail-280x222-Secrets-of-setting-up-a-mortgage-module-in-Oracle-FlexCube.webp)
![Challenges in Fine-Tuning Computer Vision Models [thumbnail]](/uploads/media/thumbnail-280x222-7-common-pitfalls-of-fine-tuning-computer-vision-models.jpg)