
Hitting Scammers Hard with ML-Based Fraud Detection Systems
Between 2015 and 2018, 60% of global banks have experienced an increase in fraud volumes and frequency:

As the chart above illustrates, card-not-present (CNP) and online fraud, in particular, have gained the most traction globally. According to the European Central Bank, CNP fraud reached €1.32 billion and accounted for as much as 73% of the total value of card fraud losses in 2016.
Personal data theft and its subsequent usage for creating synthetic identities – an elaborate scheme that assumes using a combination of real and fake, or entirely fake information to build a credit score and apply for loans – has been identified as the fastest-growing financial crime in the US in 2019. The staggering fact is that between 85% and 95% of synthetic identity applications are never picked up by traditional fraud detection analysis.
What’s even more problematic is that most financial organizations manage to recover less than 25% of their fraud losses within a year. Clearly, that’s a strong call for incorporating better fraud detection techniques in banks.
Rule-Based vs Machine Learning Fraud Detection: Why It’s Time to Switch Gears
Rule-based fraud detection systems, commonly used by financial organizations today, are intended to detect on-surface fraud indicators, e.g.: a large volume of transactions, multiple failed PIN code attempts, etc. They operate using an “IF X happens, THEN Do Y” logic, based on the set of rules and fraud scenarios, created by a human analyst. On average, banks apply around 200-300 different rules to verify the legitimacy of a transaction. Still, while the rule number may seem high, it is by no means comprehensive.
The biggest downside of the rule-based systems is that they are too straightforward – new threats require new rules. You have to explicitly program such systems to account for new types of banking or e-commerce fraud, for instance. Considering that cyber threats are getting more sophisticated and are evolving at breakneck speed, a lot of organizations need to play ‘catch up’. In other words, they are not tackling transaction fraud detection proactively. Instead, they are waiting for the precedent to emerge and then formalize it as a new rule. The human factor also comes into play here: an analyst responsible for creating new rules can provide incorrect and incomplete instructions to the system, further sabotaging its effectiveness.
Finally, rule-based systems are losing their relevance in the wake of expanding customer digital identities and the scope of interactions an average person now has online.
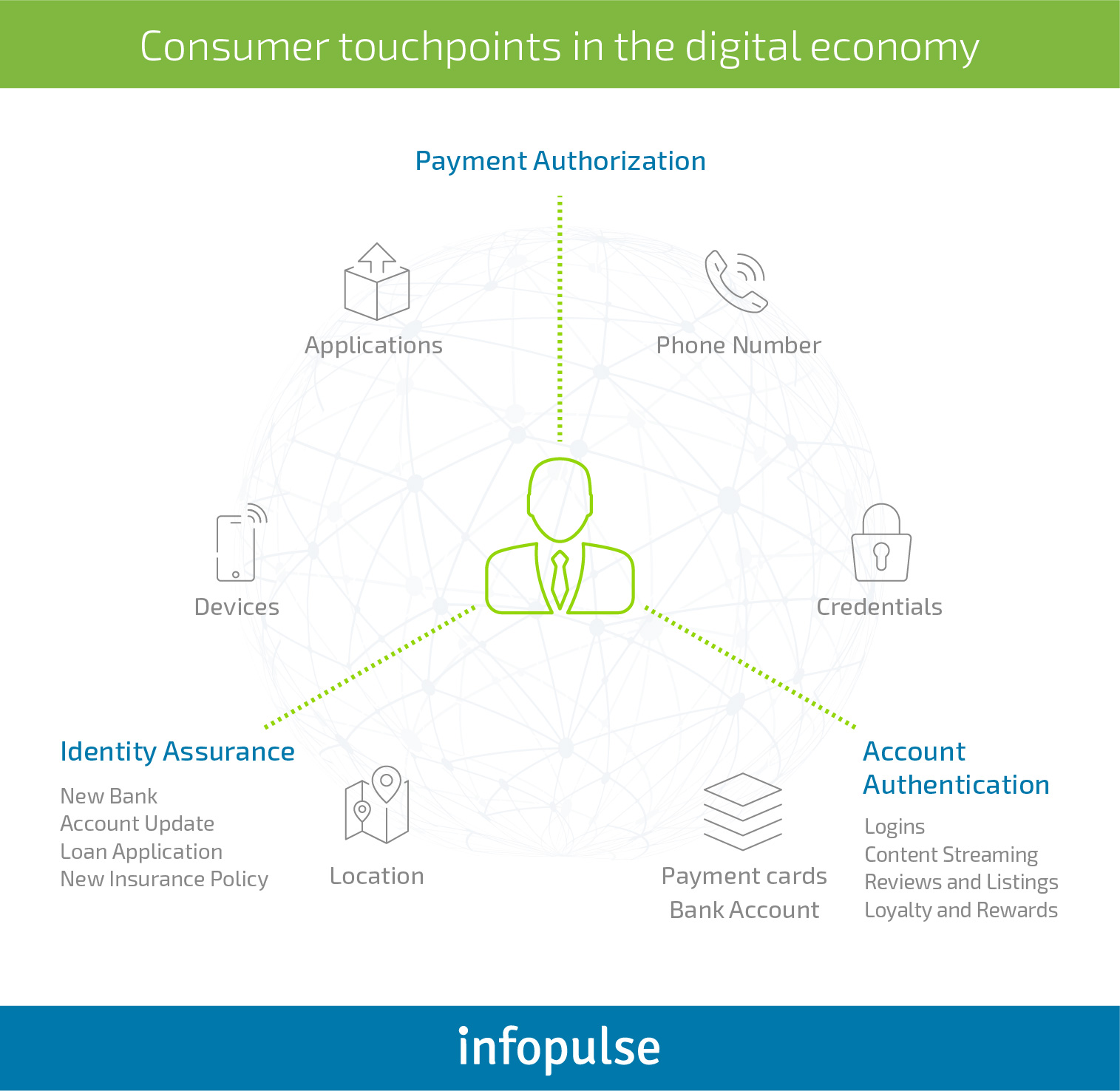
According to the illustration above, consumers utilize a multitude of payment methods and services:
- They interact with businesses online through multiple touchpoints, as well as have offline interactions.
- At the same time, the average person often treats imposed data security rules carelessly and fails to follow the necessary precautions if those are too bulky or complex.
- They often sign up for subscriptions and share sensitive data with unverified third parties, creating additional security loopholes that could be exploited.
Protecting customer’s digital identities in omnichannel banking is the new key area of concern for banks in the coming decade. It’s a challenging one too because financial institutions are under three-way pressure:
- They need to meet new compliance requirements (GDPR, PSD2, FATCA, AMLD5, etc.)
- They also need to proactively combat new types of fraud such as usage of false digital identities.
- And yet, they have to solve both of these issues without resorting to heavy-weight security approaches that would alienate customers who camp for seamless UX/CX.
Leveraging machine learning to detect fraud is proving to be the only effective way of meeting all those demands at once. Taking the ‘rule creation’ task away from human analyst to unsupervised learning/supervised learning algorithms means that you no longer need to brainstorm every possible fraud scenario – the AI will do that for you with much higher accuracy.
Machine learning algorithms can be dispatched to comb through all your datasets (with only partial instructions being given), analyze the different variables and establish repeating patterns that may signal an anomaly (fraud) or, on the contrary, define a perfectly acceptable transaction/behavior.
An ML-powered fraud detection application will also be capable of creating personalized security rules for different types of users, by assessing their digital identity through five different dimensions:
- Personal identity information
- Location(s)
- Devices used
- Usual payment and business behavior
- Threats/Bots
For instance, to reduce volume of e-commerce scam, a retailer can remove additional security steps for customers, who have already verified their identity or always log in from the same location. Alternatively, retailers can dynamically impose additional steps whenever a fraudulent device login is detected, and some unusual payment behavior takes place.
Machine Learning in Banking: Supervised and Unsupervised Models
New-gen fraud detection systems are governed by anomaly detection algorithms, proactively designed to single out unusual patterns within large volumes of data, across several dimensions. For instance, your company can take several credit card datasets containing both legitimate and fraudulent transactions, and feed them to an algorithm, so that it could establish the common patterns of good vs. bad transactions. Afterward, the system can be given the actual data for analysis and comparison against past ‘knowledge’, resulting in new respective conclusions.
Now, that was a very simplistic view of how credit card fraud detection with a neural network works. Leela Senthil Nathan from Stripe provides a more in-depth explanation of how intelligent credit card fraud detection works in this video:
Yet for now, let’s take a closer look at two different approaches for teaching ML algorithms to perform complex analysis procedures: Supervised and Unsupervised Learning.
In Supervised machine learning, an algorithm is trained on a large volume of properly labeled data. If we are talking about online transaction fraud detection, the system is provided with a dataset of transactions tagged as fraud or non-fraud. After performing the initial analysis, the system then attempts to properly classify a new set of data on its own. In a nutshell, supervised learning algorithms learn by example.
The drawback of this machine learning method is its limited scaling possibilities. You will need to constantly provide the system with labeled datasets on new types of frauds, anomalies and other malicious behavior patterns.
Unsupervised machine learning models can power more ‘out of the box’ solutions for fraud detection in banking transactions and beyond them. Such algorithms are trained with the help of deep learning techniques and artificial neural networks – software that can closely mimic human cognitive patterns and draw certain conclusions from self-learning activities. Unsupervised learning algorithms do not have to be ‘instructed’, they just need to be provided with a relevant training data set. The system will then attempt to derive the meaning directly from the data itself by analyzing it from different angles to uncover similarities and common patterns. Afterward, it applies the achieved learnings to a new data set, draws even more conclusions, and performs such learning process a couple of more times. In short, the information passes through several ‘layers’ within the neural network, each responsible for a certain assessment.
For instance, unsupervised deep learning techniques can be effectively used for e-commerce fraud prevention. An algorithm can collect and operationalize a large volume of customer data and assign a custom risk score to every buyer based on:
- Recent purchases and transactions
- Past billing, shipping, and IP addresses
- Payment methods used
- Common devices used for purchasing
- Typical browsing patterns
- Other custom data insights from your CRM and onsite analytics.
Orders that are identified as ‘high risk’ can be immediately banned and/or sent to your analyst team for further investigation.
One Japanese P2P e-commerce mobile marketplace (now operating in the UK and the US as well) recently implemented such a solution for evaluating both sellers’ and buyers’ behavior on the platform. Within three months after integration, they managed to reduce their chargeback and fraud rates by 60%.
PayPal is another example. The company also collects a huge amount of insights about its customers ranging from network to financial data information. Afterward, it’s all fed to their three-facet payment fraud detection system consisting of:
- Linear machine learning models
- Neural networks
- Deep learning algorithms
Such technological triumvirate acts as a “voting committee” on each matter, enabling the company to perform large-scale risk analysis in a matter of a few seconds. You can watch Mikhail Kourjanski, principal architect at PayPal, further explaining how this setup works:
The Benefits of Using Machine Learning for Fraud Detection
Less financial and reputational losses – aren’t those the ultimate benefits of assembling a better fraud detection system? Yes, but those two factors can be further quantified. A recent fraud analytics case study from Capgemini states that ML-powered fraud detection systems can improve detection accuracy rates by 90% and reduce fraud investigation time by 70%.
Furthermore, there are plenty of other niche fraud detection machine learning use cases that are delivering major results for different FIs.
KYC and account opening. One of the top-10 retail banks in the US has reduced the false declines for good customers by 50% after switching from manual review process to ML-based one while gaining a 70% increase in new application approvals without experiencing any additional fraud pressure.
Personal customer data theft and counterfeiting. One global credit card issuer was struggling with identifying fraudsters who used synthetic identities (created from stolen personal identifiers) to apply for credit card products. The static methods for identity verification – device ID, location and personal data – were no longer serving them well enough. The company had to switch to an intelligent behavioral biometrics solution offered by BioCatch. Their online fraud detection service monitors and identifies human and non-human behavior elements in real-time sessions, and blocks potentially malicious applications. Post-adoption, the credit card issuer experienced:
- A 33% reduction in false declines
- 50% more accurate fraud alerts when compared to other methods
- 100% of alerts are confirmed as either fraud of highly suspicious.
Prevent loan scams. Unbanked and underbanked consumers are a $380 billion opportunity for banks. However, working with such populations also poses an additional risk burden, especially for online lending products. To stay on the safe side, an FI needs to reconcile static identity data obtained from credit bureaus and other agencies or online sources with real-time data about the users’ device, location, and behavioral pattern.
ThreatMetrix recently helped one P2P lender upgrade their identity assessment process for loan applications that resulted in the following:
- Low fraud rate: 0.12% on all loan applications.
- Such a low rate has allowed the lender to eliminate the need for a fraud protection fund.
- The new fraud detection system for loan applications became the backbone for the automated approval process, significantly reducing the manual work.
Conclusions
Machine learning and deep learning are two robust technological solutions for enabling data-driven fraud detection – a self-learning system, capable of operationalizing both static and real-time information. However, developing and implementing machine-learning solutions will require significant domain expertise and a high level of organizational data maturity.
To better assess the scope of transformations and infrastructure changes that may be required for implementing new fraud detection systems, schedule a discovery session with one of Infopulse data science consultants.
![CX with Virtual Assistants in Telecom [thumbnail]](/uploads/media/280x222-how-to-improve-cx-in-telecom-with-virtual-assistants.webp)
![Generative AI and Power BI [thumbnail]](/uploads/media/thumbnail-280x222-generative-AI-and-Power-BI-a-powerful.webp)
![AI for Risk Assessment in Insurance [thumbnail]](/uploads/media/aI-enabled-risk-assessment_280x222.webp)
![Super Apps Review [thumbnail]](/uploads/media/thumbnail-280x222-introducing-Super-App-a-Better-Approach-to-All-in-One-Experience.webp)
![IoT Energy Management Solutions [thumbnail]](/uploads/media/thumbnail-280x222-iot-energy-management-benefits-use-сases-and-сhallenges.webp)
![5G Network Holes [Thumbnail]](/uploads/media/280x222-how-to-detect-and-predict-5g-network-coverage-holes.webp)

![How to Reduce Churn in Telecom [thumbnail]](/uploads/media/thumbnail-280x222-how-to-reduce-churn-in-telecom-6-practical-strategies-for-telco-managers.webp)
![Automated Machine Data Collection for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-how-to-set-up-automated-machine-data-collection-for-manufacturing.webp)
![Money20/20 Key Points [thumbnail]](/uploads/media/thumbnail-280x222-humanizing-the-fintech-industry-money-20-20-takeaways.webp)