![BCDR for smbs [banner]](https://www.infopulse.com/uploads/media/banner-1920x528-business-continuity-and-disaster-recovery-planning-for-smbs-and-enterprises.webp)
Business Continuity and Disaster Recovery Planning for SMBs and Enterprises
What is Business Continuity Planning and Disaster Recovery?
Business continuity planning (BCP) is the process of ensuring stability and fast resumption of business functions after a disruption. Disruptions can include a system glitch, unplanned downtime, cyber-attacks, or other unforeseen events.
BCP includes operational (policies, procedures) and technology (data backup sites, service failover architecture, etc.) components, implemented to ensure fast business systems and data recovery.
Disaster recovery mechanisms are the key element of effective BCP.
Disaster recovery (DR) is a standardized, tech-driven procedure for regaining access to IT infrastructure following an unforeseen event. Disaster recovery plans are based on preliminary risk analysis and include mitigation strategies for ensuring alternative means of operation and the rapid recovery of services.
Combined disaster recovery and business continuity planning limit the impacts of potential disruption and improve the company’s risk management capability and operational resilience.
Convergence of Business Continuity and Disaster Recovery (BCDR)
Traditionally, BC and DR existed as two complementary, yet separate activities.
In a traditional model, business continuity is a “before” practice, which included risk modeling and business performance analysis under different conditions. Typically, BCP was driven by the business units and focused on ensuring the fast mobilization of responsible personnel, recovery teams, and external support.
Disaster recovery, in turn, was an “after” activity, aimed at ensuring a rapid restoration of IT infrastructure and digital systems. DR planning and execution were mainly done and executed by the IT function.
Yet, as the levels of corporate reliance on IT infrastructure have increased dramatically, BCP and DRP can no longer exist as standalone activities.
The global pandemic has accelerated the digitization of customer interactions by 3-4 years across regions. Likewise, businesses have grown critically dependent on uninterrupted access to technologies, the lack of which results in significant losses. Per Uptime Institute’s 2022 Outage Analysis Report, 60% of outages generated over $100,000 in losses for the affected organizations, with 15% resulting in over $1 million in associated costs.
Moreover, risk teams today have grown increasingly reliant on technologies for improved analysis, decision-making, and planning in the risk function. In fact, risk managers view the implementation of new technologies as their top priority for navigating an extended risk radar.
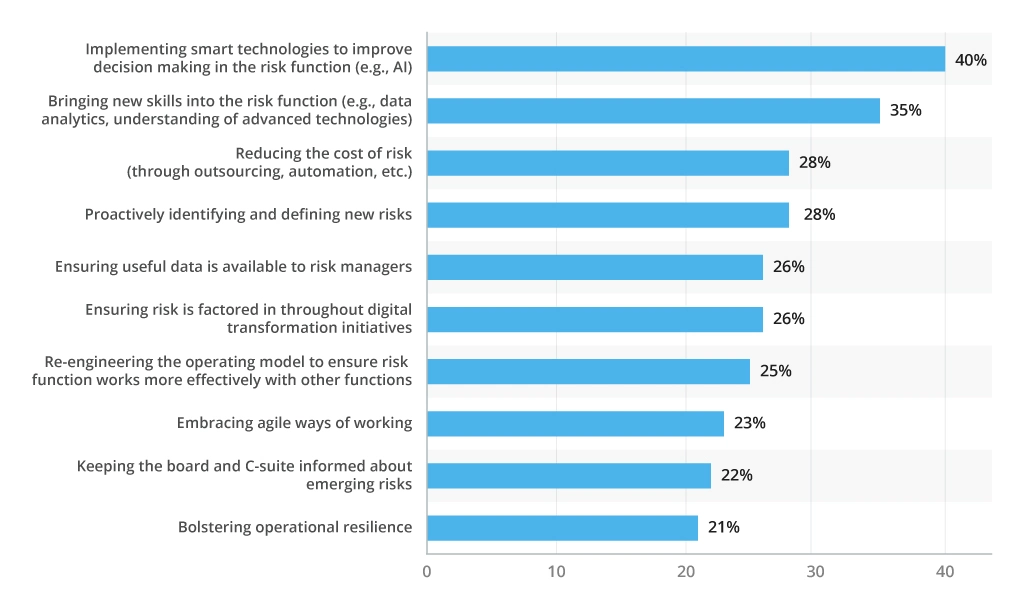
The strong dependency of businesses on technologies calls for a converged approach to business continuity and disaster recovery.
BCDR Implementation: Best Practices and Solutions
Technological risks such as “digital inequality” and “cybersecurity failures” were identified as critical short- and medium-term threats to the world according to the Global Risks Report 2022 by the World Economic Forum.
When Amazon experienced one of its worst service outages in history due to subpar IT infrastructure configurations, the company reportedly lost $1.2 million per minute in sales. At the end of 2022, British Airlines had to ground most of its North American-bound aircrafts due to technical issues in its long-haul flight planning system, which resulted in major operational and reputational losses.
Although the majority of business leaders understand the importance of planning ahead for adverse events, far fewer actually implement effective BCDR solutions. Only 54% of organizations had a documented company-wide disaster recovery strategy. At the same time, 43% of organizations experienced unrecoverable data loss in 2021.
Implementation complexities and costs are a common “excuse” for not following through with BCDR implementation. Yet, given that the average cost of a data breach for SMBs is $108K, investments in BCDR pay for themselves manyfold and generate a solid return on investment.
Cloud-based disaster recovery solutions from Microsoft such as Azure Site Recovery and Azure Backup have predictable and flexible costs. Since secondary services failover sites only need to be activated in case of a disruptive event, you do not have to over-pay for extra idle hardware or idle cloud capacities.
In this section, we illustrate how small, mid-market, and enterprise-sized companies across industries can implement lean, fail-proof BCDR architectures using Azure infrastructure.
Create a Cloud Backup for Essential Business Services
A disaster recovery plan should include undisrupted access to critical business systems (e.g., digital workplace applications or document management systems) as a minimum viable measure.
Disaster Recovery as a Service (DRaaS) solutions such as Azure Backup allows businesses to implement cost-efficient data and application backup to the cloud.
In case of a disruption, a switchover to the alternative site will be activated automatically within minutes, meaning that business users will not experience many interruptions to their workflows.
Moreover, Microsoft gives you the flexibility to use either their native data backup service (Azure Backup) or a third-party solution, in combination with Azure Blob Storage — a highly secure, cloud data platform with geo-replication across regions.
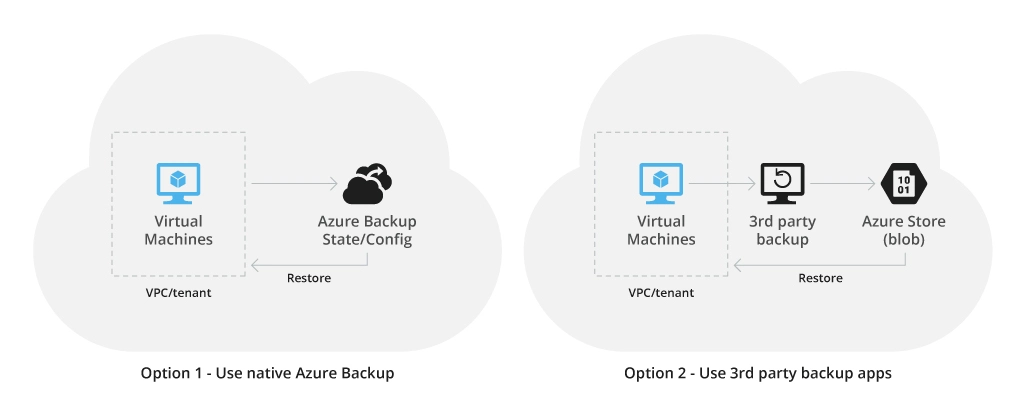
Note that this scenario only assumes backups of certain business applications and data. Therefore, you might lack access to other IT resources in the event of a large-scale system failure or incident at your physical facility.
Implement Service Failover for Critical Infrastructure
Partial BCDR plans, as described in the previous section, deliver limited protection. In case of a severe event, you might experience critical data loss. In fact, IDC found that among 79% of businesses that had activated a disaster response within the past 12 months, 60% had experienced unrecoverable data loss within this time.
If data continuity is a critical service-level and/or compliance requirement, consider implementing full services failover for the most critical IT infrastructure components — individual applications, servers, and local data storage facilities.
Failover is a backup process of transferring the operation of a service from a failed system to a stand-by alternate.
The failover mechanism ensures that the affected system remains accessible to users despite the disruption. Automatic failovers can (and should be) programmed for any business-critical application, database, server, or network.
SMBs typically rely on simpler failover strategies, such as manual failover or hot standby for on-premises systems, while larger organizations may have more complex failover architectures that involve multiple data redundancy sites and automated failover processes to cloud-based cold or warm failover sites.
Microsoft Azure provides a host of BCDR solutions for implementing failover scenarios of various complexity, using cloud, hybrid, and on-premises architecture.
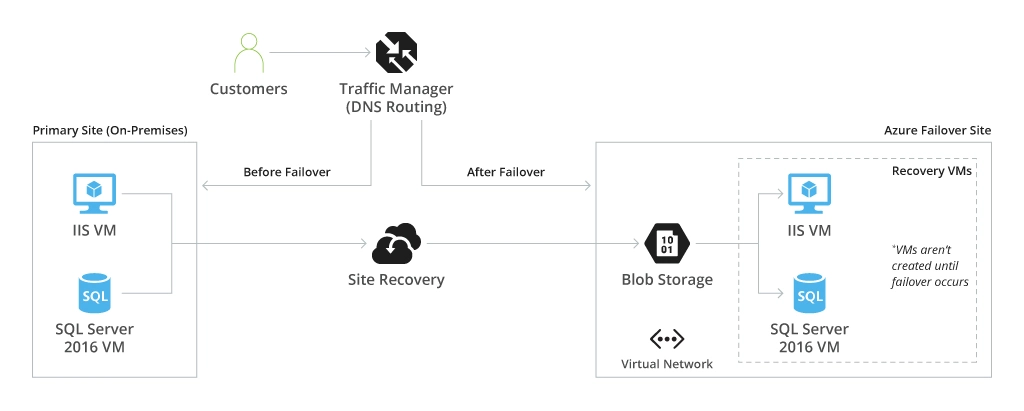
With Azure Site Recovery you can program seamless, condition-based workload replication from the primary to a secondary location. Doing so would ensure access to the backup systems in case of a disruptive event. Azure Blob Storage contains copies of all virtual machines that are protected by Site Recovery.
Azure Traffic Manager is a DNS-based load balancing, used for routing traffic between different sites. Depending on your latency and availability requirements for different systems, you can choose to implement:
- Manual failover, which requires manual activation by the IT engineering team
- Automatic failover, auto-executed based on the pre-defined conditions
Automatic failover scenarios, however, may be more expensive since you are required to maintain a warm failover site — such as those that have instances of auto-scaling switched on and maximum infrastructure configurations activated. The advantage, however, is a faster near-real-time recovery point objective (RPO) and recovery time objective (RTO).
Consider Implementing a Secondary Data Center
Larger organizations, requiring maximum system uptime (above 99.999%) and minimal data latency across branches should consider implementing a second availability zone for their business.
A second availability zone can be either on-premises based (i.e., a secondary data center in another geographic region) or cloud-based (i.e., hosted with an alternative public or private cloud provider).
The advantage of establishing a secondary cloud-based site is end-to-end business service replication and restoration experience in case of a disruption. The uncapped flexibility of cloud solutions also eliminates TCO, associated with hardware procurement and maintenance, which on-premises data centers require.
Microsoft Azure allows the creation of multiple service failover scenarios to meet specific SLAs and data replication needs for different applications.

In each case, all data is backed up to Azure Elastic Storage. Failover Azure VMs are then created based on the replicated data. The VM replication frequency can be as low as 30 seconds.
Unlike legacy data backup solutions, Azure Site Recovery also captures data in memory and all transactions in process for replicated applications, minimizing the risks of data loss. Moreover, the service allows the creation of advanced failover sequences for multi-tier applications running on multiple VMs.
Cybersecurity: the Final Pillar of BCDR Planning
Although service continuity remains the primary objective of BCDR, cybersecurity is another area worth including in your strategy. An average organization now experiences over 270 cyberattacks per year, of which 29 end up being successful.
Therefore, comprehensive BCDR plans now include a security component, aimed at minimizing:
- System downtime in case of a security event
- Attack surface and operational exposure.
IT infrastructure components containing and processing sensitive data include an effective data backup and restoration strategy. Automatic failover to secondary sites is often recommended for the highest possible scores on the recovery time objective and recovery point objective
Additionally, all secondary sites must be properly secured and pen-tested to prevent malicious actors from launching a secondary vector of attack.
Successful BCDR Implementation: Infopulse Case Study
As a software engineering partner to global businesses, Infopulse realizes the critical importance of unhalted operations. In 2016, we began the corporate BCDR plan design and staged implementation.
Our goal was to create a redundant, resilient, hybrid IT infrastructure, which would ensure the topmost protection of the key corporate systems.
In 2019, we established a secondary data center in the EU, which allowed us to be even more interconnected with our parent company Tietoevry and other European business partners. However, due to the geopolitical developments in Ukraine, we decided to convert the established data center into a primary site and successfully migrated most operations to the cloud.
As part of our BCDR plan, we fully migrated all corporate communication systems (emails, intranet, and rights Management center) to the cloud. By January 2022 we had achieved a 100% test score with all 46 Product IT systems covered. We would be delighted to help our clients achieve the same outcomes.

![CX with Virtual Assistants in Telecom [thumbnail]](/uploads/media/280x222-how-to-improve-cx-in-telecom-with-virtual-assistants.webp)
![Power Apps Licensing Guide [thumbnail]](/uploads/media/thumbnail-280x222-power-apps-licensing-guide.webp)
![Expanding NOC into Service Monitoring [thumbnail]](/uploads/media/280x222-best-practices-of-expanding-telecom-noc.webp)
![Cloud-Native for Banking [thumbnail]](/uploads/media/cloud-native-solutions-for-banking_280x222.webp)
![Generative AI and Power BI [thumbnail]](/uploads/media/thumbnail-280x222-generative-AI-and-Power-BI-a-powerful.webp)
![Data Governance in Healthcare [thumbnail]](/uploads/media/blog-post-data-governance-in-healthcare_280x222.webp)
![Super Apps Review [thumbnail]](/uploads/media/thumbnail-280x222-introducing-Super-App-a-Better-Approach-to-All-in-One-Experience.webp)
![SAP Service Insight [thumbnail]](/uploads/media/Service Insight-Infopulse-SAP-Vendor-280x222.webp)
