
Why Converging a Data Warehouse and Data Lake is the Path Forward for Analytics-Driven Companies
Enterprises will also need more computing power, storage, and data management to access this intel. Up until recently, the two standard options for storing corporate data were data warehouses (as an extension of relational databases) and data lakes. However, the growing volumes of data can no longer fit into one solution, prompting many to consider hybrid architecture scenarios.
Data Warehouse vs Data Lake: Core Concepts Explained
Before we go into the discussion about the convergence of the two technologies, here is a quick refresher of the terms.
What is a Data Warehouse?
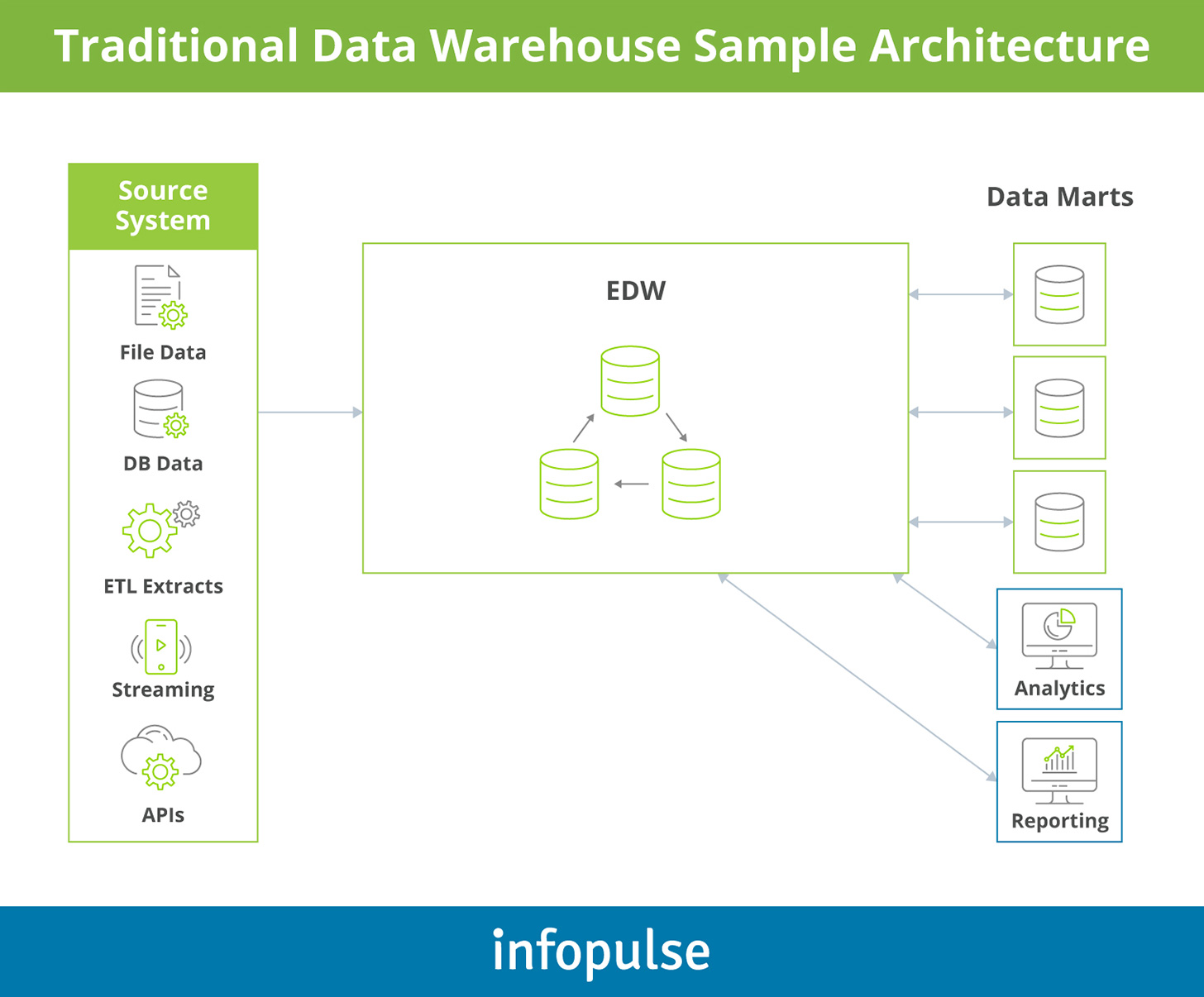
A data warehouse (DW) is a technical system, sitting atop of the traditional databases, that accumulates, transforms, and stores data from different sources in an analytics-ready state. Enriched data is stored in respective quantitative metrics with their attributes. Such systems act as catalogs providing a multidimensional view of atomic and summary data.
Data warehouse solutions enable business leaders to connect business intelligence (BI) tools and advanced big data analytics solutions, powered by machine learning (ML) and artificial intelligence (AI) to parse through the pre-cleansed data and transform it into actionable business insights for better decision-making. For example, you can use SAP HANA to consolidate all your corporate data for analysis and then easily connect a set of business analytics tools such as SAP Business Objects.
Learn more about SAP data warehouse development.
Data Warehouse Benefits
- Faster and more robust BI
- Improved data quality and conformity
- Access to historical insights
- Scalability and interoperability
- Enhanced data security and compliance
- Data consolidation and elimination of silos
What is a Data Lake?
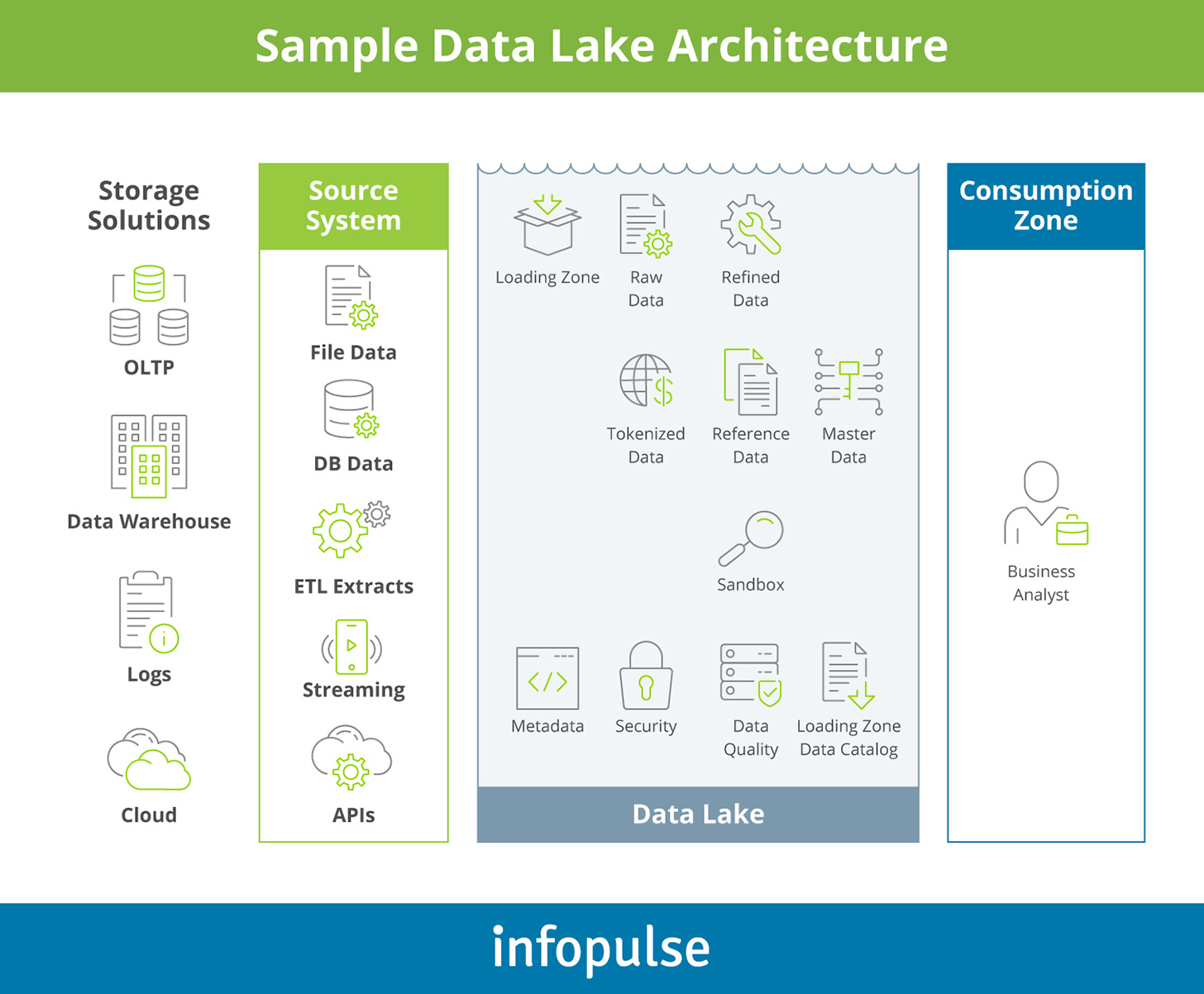
A data lake is another solution for aggregating structured and unstructured big data from connected sources into secure, scalable cloud storage. Unlike data warehousing, the collected data is stored in state — without any prior transformations, cleansing, or cataloging. Cloud-based data lake solutions can accommodate large volumes of big data with no limits on file sizes.
Data lake technologies support the storage of relational and non-relational data without any schema markups, but with metadata captured. Meaning you can accumulate raw intel for further analysis and transform it later into a suitable format for a specific research task, e.g., real-time analytics or text mining.
Data Lake Benefits
- Higher data processing speed
- Continuous data ingestion
- Flexibility to explore different analytics use cases
- Fast response times
- Numerous ways of querying the data
Data Lake vs Data Warehouse: Comparison Table
Data lake
Data warehouse
Data format
Raw. Any structured, semi-structured, and unstructured data can be stored. Schema applied on read-only.
Cleansed. Schema needs to be defined before data is stored. Data needs to be pre-transformed and enriched.
Scalability
Virtually unlimited. Can accommodate zettabytes of data at an affordable cost.
Moderate-to-large. Cloud-based DWs can accommodate significant volumes of data, but the storage costs are higher.
Workloads
Supports batch processing, high-concurrency workloads, and rapid big data querying.
Supports batch processing and high-concurrency workloads.
Data processing principles
OLTP. Online Transaction Processing.
OLAP: Online Analytical Processing.
User experience
Best suited for data scientists and engineers looking for raw data to support an analytics use case.
Best suited for operational users, requiring hot-key access to interpretable data for analysis.
Operational tasks
Best suited for exploring open-end research questions.
Best suited for getting answers to predefined questions.
Hybrid Data Lake: Converging Data Warehouses with Data Lakes
The growth of big data volumes and usage has prompted many business leaders to re-think their strategy to storing and processing data. Cloud data warehouses offer flexible data storage, but the major limitation is the ability to wrangle with data. Data warehouse technologies force you into using a specific format, compatible with existing BI tools. This means that not all types of data are available for analytics. Moreover, you are limited in terms of the toolkit you can apply.
For the above reason, market leaders are sizing up data warehouse augmentation — adding a complementary data lake to the data management setup to support a wider range of analytics use cases.
Such a data warehouse modernization scenario does not imply retiring existing tech assets. On the contrary, you continue relying on DW for the same set of tasks but add complementary data streams and analytics capabilities through data lake implementation.
Here is how such a setup can work:
- All unstructured and untransformed data is first loaded to the data lake. In this case, you can ingest both SQL and NoSQL data from an array of data sources — ERP or CRM systems, external marketing analytics tools, customer support systems, social media, public data sources, geospatial platforms, and more.
- Based on the captured metadata, data engineers can tap into the lake to look for relevant datasets and sources to deploy custom algorithms for anomaly prediction, predictive maintenance, or fraud detection.
- Certain portions of data can also be transformed via an extract-transform-load (ETL) process and uploaded to a connected cloud-based data warehouse in a structured form. After being transformed to a suitable format, it can be used by self-service BI tools, data visualization software, and other analytics tools including legacy ones.
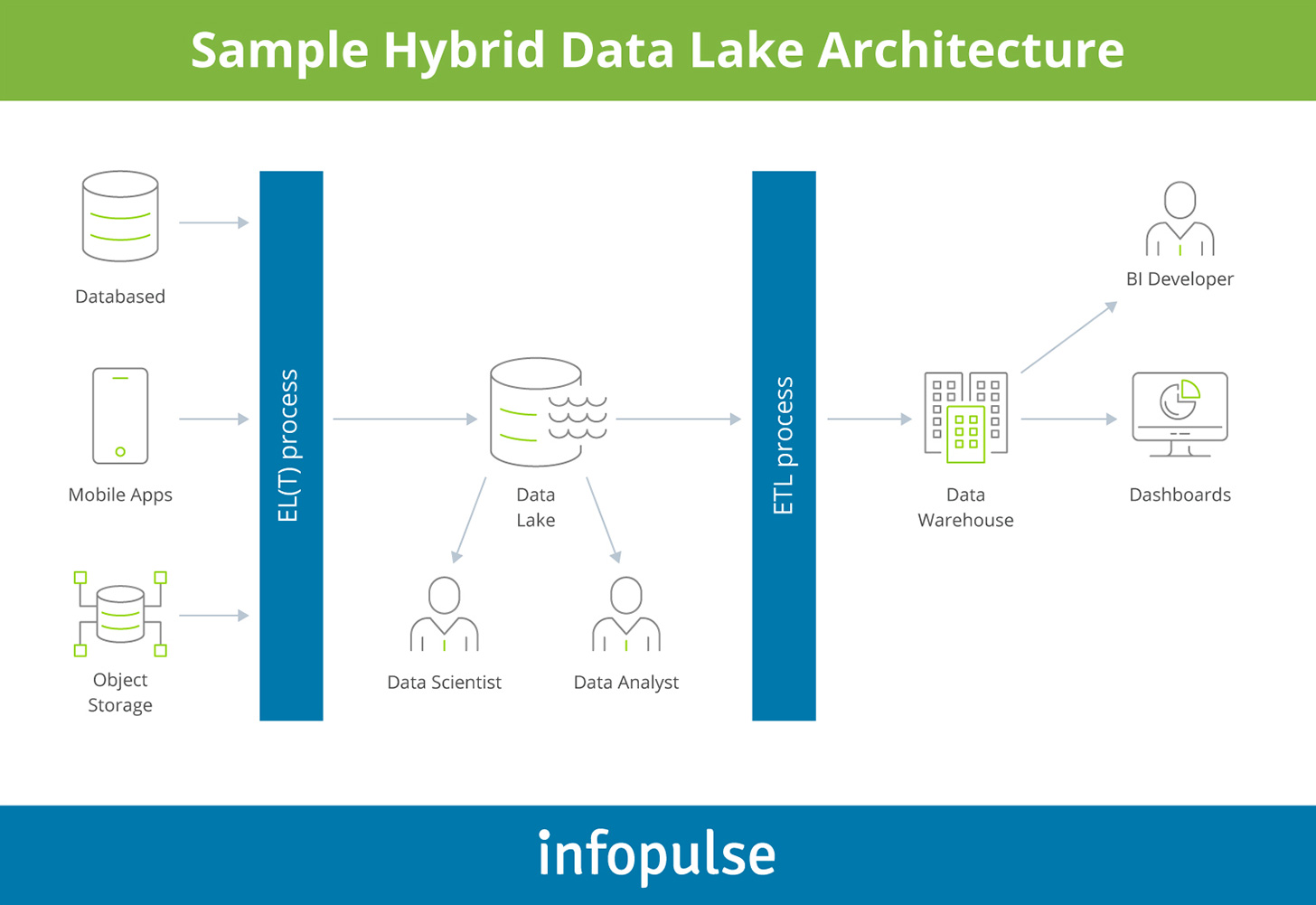
To create a similar setup you can use the following host of technologies:
- ELT/ETL process using Azure Data factory or Google Cloud Data Fusion
- Data lake using Azure Data Lake Store or AWS Athena & S3
- Data warehouse using Snowflake, Azure SQL Data Warehouse, Google BigQuery, or AWS Redshift
In essence, a data lake in this case acts as a “catcher”, assembling all available data and then enabling the partition of certain data for different types of analysis.
Therefore, you have two environments for all data:
- Data lake — a ‘sandbox’ environment with raw data, stored at a more affordable cost, and rapidly retrievable for analysis.
- Data warehouse — a serving and compliance environment, accessible to a higher number of users who can query the enriched data using an array of tools.
Why Implement Both Data Lake and Data Warehouse Technology
Gartner states that by 2022, 90% of corporate strategies will mention analytics as an essential competency. EY data also mentions that last year, 62% of companies increased the usage of data solutions and digital technologies.
The figures above indicate strong ambition towards data analytics excellence. However, when it comes down to execution, most leaders get stalled by the data accessibility and data quality — an issue hybrid data lakes are meant to tackle.
The modern data warehouse best practices encourage organizations to “divide and conquer” the mounting volumes of data:
- Traditional DWs (hosted on-premises or in the cloud) can retain their core reporting function and act as the “single source of truth” for self-service BI tools.
- A data lake, in turn, can serve as a multipurpose repository, enabling the development of custom algorithms and predictive analytics models.
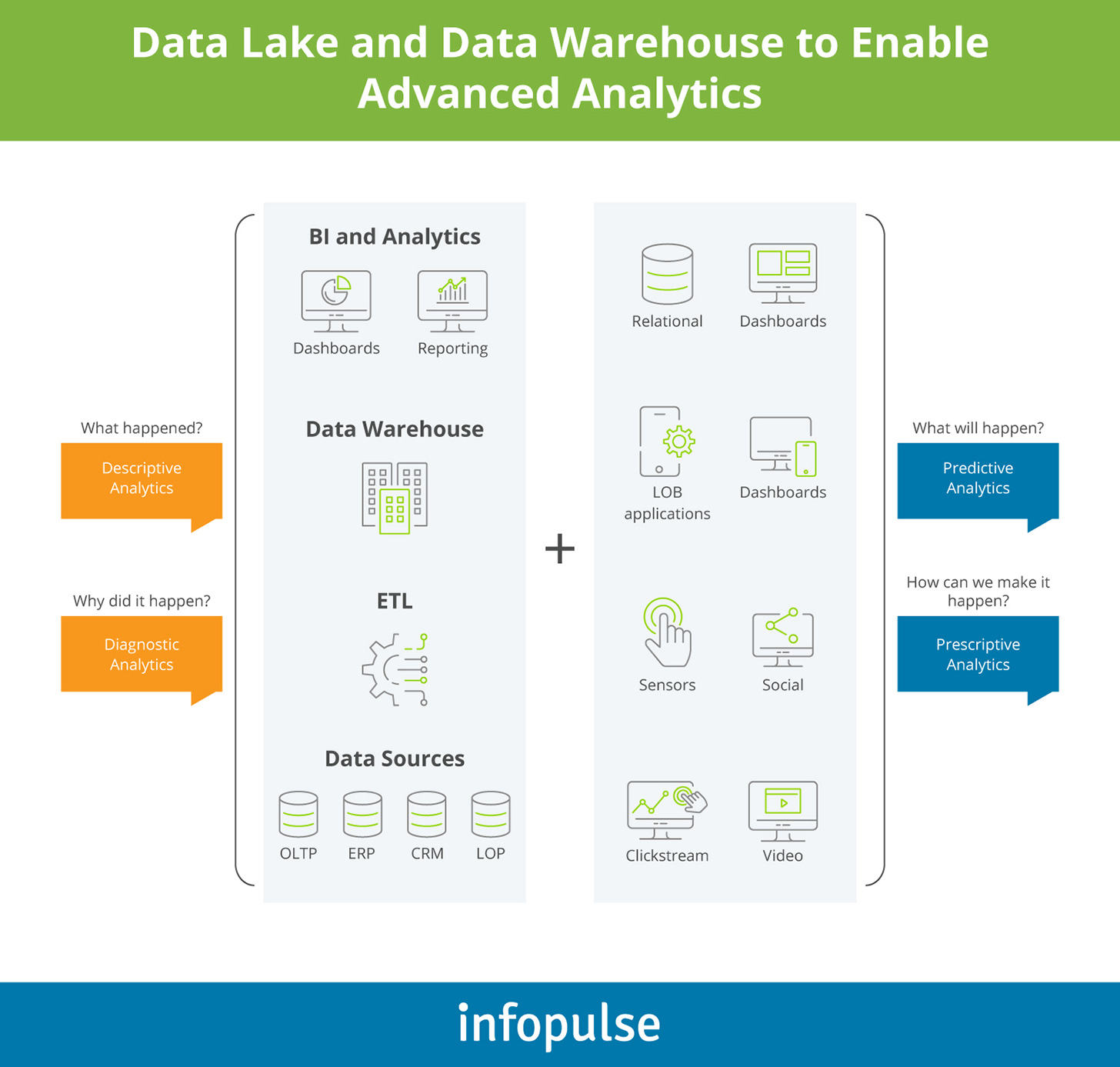
By segregating workloads and data storage, you can not only offset the data storage costs, but also improve data visibility, governance, and security across the board.
The Benefits of the Hybrid Data Lake Strategy
- Federated querying: Such a setup enables you to query relational and non-relational data using a single retrieval query, instead of different tools and processes (such as EFL). Doing so increases your teams’ productivity, plus enables you to create pipelines that extract data from different sources.
- Lower storage costs: Data lake solutions such as Azure Data Lake and Amazon S3 are a more cost-competitive option to on-premises data storage. Additionally, since the majority of data will be hosted in a more affordable data lake system, a lesser fraction of costs will be spent on data transformation and storage in DWs.
- Rapid data processing: With parallel batch processing and schema-on-read, you can load more data to the data lake when compared to a data warehouse. This enables faster time-to-market for new analytics solutions.
- Limitless experimentation: A hybrid setup lets you run concurrent workloads on the same datasets and re-use available data for different analytics purposes. Moreover, storing data in raw format does not limit data scientists to using specific statistical analysis or data modeling techniques.
- Improved security and compliance: The dual setup allows you to segregate sensitive data from entering the data lake and, instead, re-route it straight to the data warehouse for further transformations. Respectively, you have better visibility and control over data usage and compliance as opposed to using a data lake only.
- Enhanced interoperability: Hybrid data warehouse enables access to a wider range of data sources — from IoT devices to public web data. You can set up data integrations with any type of application with an open API to harness even more data for analysis.
- Faster rate of experimentation: Readily available, reusable data means that your team can explore a wider range of research questions, experiment with different data science models and machine learning algorithms to bring innovative solutions to the market faster.
To Conclude
Data warehouses and data lakes have respective strengths and limitations. While the lake allows you to store significant volumes of diverse data, this architecture presents challenges in terms of data updates, visibility, reconciliation, and compliance. Effectively governing data from many disparate sources is technologically challenging.
Warehouses, on the other hand, promote data consistency, homogeneity, and quality. However, this comes at a higher and slower data processing cost, plus often limits you to SQL-based queries only. Scaling such solutions is less affordable as both the storing and computing costs increase.
A hybrid approach capitalizes on the strengths of both solutions while offsetting the pain points of operating such systems individually. Given the growing volume and diversity of data and, subsequently, analytics use cases, it becomes impossible to fulfill all of them with a single solution. Thus, if “data excellence” is a priority on your agenda as well, the hybrid architecture may be the optimal approach to achieving this goal.
If you would like to learn more about different approaches to data warehouse augmentation and modernization, contact Infopulse experts.

![Generative AI and Power BI [thumbnail]](/uploads/media/thumbnail-280x222-generative-AI-and-Power-BI-a-powerful.webp)
![Data Governance in Healthcare [thumbnail]](/uploads/media/blog-post-data-governance-in-healthcare_280x222.webp)
![AI for Risk Assessment in Insurance [thumbnail]](/uploads/media/aI-enabled-risk-assessment_280x222.webp)
![IoT Energy Management Solutions [thumbnail]](/uploads/media/thumbnail-280x222-iot-energy-management-benefits-use-сases-and-сhallenges.webp)

![Carbon Management Challenges and Solutions [thumbnail]](/uploads/media/thumbnail-280x222-carbon-management-3-challenges-and-solutions-to-prepare-for-a-sustainable-future.webp)

![Automated Machine Data Collection for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-how-to-set-up-automated-machine-data-collection-for-manufacturing.webp)

