
Anomaly Detection Solutions for Predictive Maintenance of Industrial Equipment and Systems
The airline industry alone spends a collective $70 billion on maintenance – twice more than it takes away as profit. In the wind energy sector, O&M costs are predicted to hit $17 billion in 2020 – a nearly two-fold increase since 2014. In both cases, the cost spike comes as a result of aging equipment, inefficient service scheduling and lack of visibility into actual wear and tear.
The airline and the energy industries are not the only ones losing revenue as a result of reactive maintenance. In fact, most heavy industrial companies still rely on outdated servicing practices for their equipment, resulting in higher downtime.
Predictive maintenance, powered by Big Data analytics and machine learning, recently came to the fore as an effective solution to these troubles. However, most predictive maintenance techniques will fall short without:
- A good historical data range of potential failure types
- Normal equipment performance thresholds
- Data suggesting what conditions foreshadow failure.
To make accurate predictions, you’ll first need to establish an equipment data collection process, then learn to detect normal and abnormal behavior, and only afterwards train the algorithms to make predictions.
In this post, we propose to take a closer look at anomaly detection as an imperative step for predictive maintenance (PdM).
The Key Technologies Underpinning Predictive Maintenance
Back in the day, regular equipment inspections were required to collect performance data. Today, industrial IoT solutions are effectively replacing humans in this role. By 2020, 72% of manufacturing companies surveyed by PwC plan to majorly increase their level of digitization to reach the ranks of “digitally advanced”, up from 33% in 2018. Specifically, they are investing $907 billion per year in greater connectivity and smart factories.
Several factors are contributing to the ramped-up levels of digitization:
- Increased data storage and data processing capacities thanks to cloud computing.
- Improving costs and quality of sensor, device and asset-level connectivity
- Commoditization of Big Data analytics, machine learning, and AI technologies.
All of the above has enabled organizations to get better at capturing the slightest deviations in systems and equipment performance. Further, by combining historical and present real-time data from sensors, along with additional sources on failure rates, operators can now predict when the anomalies are likely to happen and take proactive steps to mitigate them.
Predictive analytics helps manufacturers uncover previously hidden occurrences, boost and maximize the performance of individual assets or even the performance of the entire supply chain.
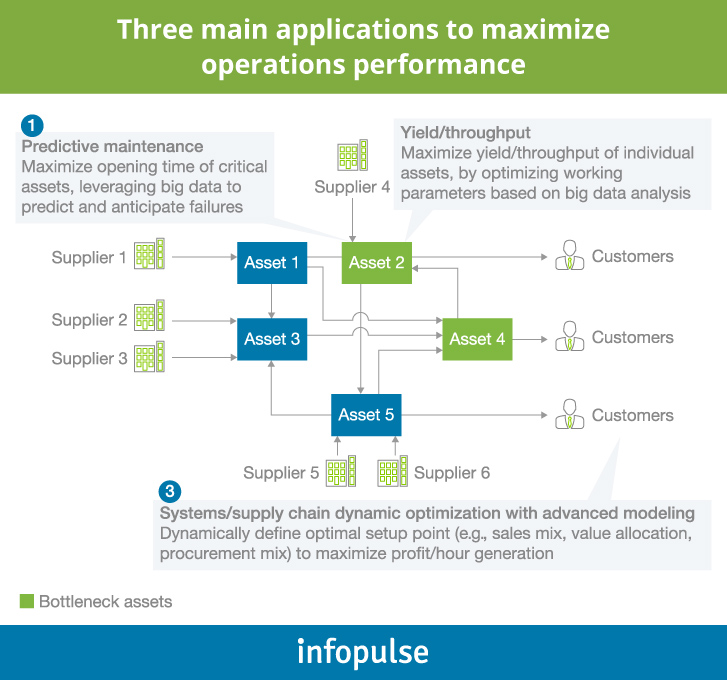
As we wrote in our previous post about real-time anomaly detection, there are several technological approaches to enable predictive analytics and ultimately, predictive maintenance (PdM).
Depending on the type of data you have, you can develop anomaly detection algorithms using either of the following methods:
Category
Method
Statistical anomaly detection
- Univariate
- Multivariate
- Time series model
Machine learning anomaly detection
- Bayesian networks
- Markov models
- Neural networks including Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs)
- Isolation Forest with visualizations
- Genetic algorithms
- K-nearest neighbor
- Decision trees
- Clustering and outlier detection
For analyzing data obtained from a single sensor, we have found Donut unsupervised anomaly detection algorithm to be particularly effective. Donut algorithm is based on variational autoencoders (VAEs) – a deep learning-based model, capable of producing new, unseen data. This distinctive feature makes them particularly effective for image rendering tasks and anomaly detection. However, unlike standard VAEs, it yields higher accuracy results for unsupervised learning and detects a wider array of anomalies within the given data.
For operationalizing multi-sensor data, the Isolation Forest technique, paired with visualizations, works even better. In this case, you can also create unsupervised models that first assess cumulatively the provided data across several metrics (10+ for instance) to find an anomaly, and afterwards, analyze individual metrics to ensure whether there are any granular anomalies. Such two-pronged approach enables companies to capture the slightest deviations in performance early on and investigate those further.
Isolation forest is one of the newer and rather different techniques for detecting anomalies, but it’s a strong technological contender because:
- They have lower memory requirements compared to other methods.
- Time-to-train is faster
- Lower linear time complexity means that such models deliver results faster, and, potentially in real-time.
In short, these two techniques underpin our proprietory anomaly detection solution.
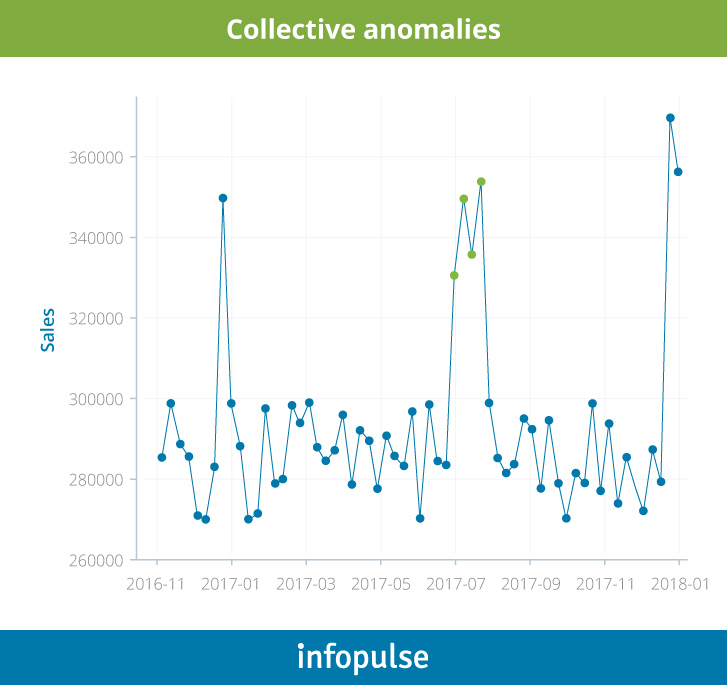
Manufacturing
Temperature, sound, vibration, visual state – are just a few of the indicators telling operators if their equipment functions the way it should. Any anomaly in either of these metrics can indicate the onset of failure. IoT sensors can effectively capture all of the information above and transmit it in real-time to the anomaly detection system for “inspection”. Then, the algorithm (such as Donut) can compare the current parameters from a sensor to historical ones, as well as external data on normal performance, and alert the operators about possible issues.
One real-time anomaly detection case study illustrates how a variational autoencoder can be used to detect abnormalities in equipment vibration patterns with high precision. Specifically, the company needed a better way to detect micro-cracks in molds used for presswork. Tiny cracks are impossible to notice during a visual inspection, thus they attached a microphone collecting the sound of the equipment at work work. Equipment with the tiny scratches didn’t sound the same way as the new ones did. The algorithm managed to detect 90% of the anomalies that were further confirmed to be signs of equipment wear.
Furthermore, after expanding their anomaly detection dataset, this manufacturer could have also added predictive maintenance algorithms to their setup and train the system to predict wear & tear failure and suggest the optimal inspection/maintenance windows.
Oil & Gas
Oil & Gas industry already produces a wealth of data that could be put to better action using predictive maintenance tools:

In particular, various anomaly detection techniques can be used to detect failure and degradation in:
- Gas compressors
- Compound systems in oil refineries
- Mechanical rig damage
- External and internal equipment leaks at offshore rigs
When it comes to offshore operations, IoT predictive maintenance can be a major game-changer. Smart sensors can seamlessly capture various wear and tear indicators – the root cause of equipment failure in 53% of incidents reported by operators in the Gulf of Mexico. This, in turn, can prevent costly downtime and vastly improve O&M costs.
IoT devices can capture the following types of data:
- Mechanical stressors: pressures, fretting movement, residual and applied stress;
- Thermal exposure: high equipment temperature causing material degradation;
- Environmental stressors: reaction of materials to aggressive environments;
- Radiation exposure: Impact of ultraviolet light, sunlight and ionizing radiation on equipment.
All of the above can be then transmitted to an anomaly detection system that would benchmark these against historical patterns and capture the changes. As the last step, predictive maintenance software would estimate how the detected anomaly would impact equipment performance. Any critical issues would be immediately reported.
Let’s further illustrate this with an example of a compound system at an oil refinery. The following five types of anomalies can signify major issues in the operations:
- High-temperature gas leakage
- Low-temperature gas leakage
- Deviations in rotor bearing
- Abnormal temperature increase
- Issues in pipe internal flow (cavitation, control valve noise, etc.).
Operators can collect this type of information by installing the following sensors:
- Infrared image sensor and acoustic sensor to detect gas leakage
- Pressure sensors to identify abnormal pipe flows
- Acoustic and vibration sensors for faulty rotor detection
- Visible and infrared image sensors to record temperature increase.
With the help of real-time anomaly detection techniques, you can immediately gauge any change in data, while predictive maintenance technology will indicate how critical the anomaly is and whether it already indicates failure or merely the onset of it.
Energy & Utilities
The Energy sector is one of the most rapid adopters of IoT technology. By 2027, it’s predicted to surpass $108,298 million, growing at a CAGR of 17.3%. To a large extent, this growth will be ushered by greater adoption of predictive maintenance.
Asset downtime and O&M costs, especially for green energy production, are a well-known revenue drain for energy producers. The IoT, anomaly detection and predictive maintenance triumvirate can change that. Power lines, power stations, and key equipment can be “plugged in” the PdV system to identify underperforming assets in real-time and predict the remaining machinery lifetime.
APS, one of the largest utility providers in Arizona, recently shared their success story in this domain. In 2018, the company connected over 300 plant assets to a machine learning-based anomaly detection software that helped detect 14 critical failures. In 2019, they expanded their system to two other plants in partnership with a predictive maintenance company, Petasense. At present, APS can remotely monitor the 1000+ balance of plant rotating machines using vibration sensors and predictive analytics and maintain top service levels.
You can find more case studies in our previous post about IoT predictive maintenance in the wind energy sector.
Telecom
For Telcos, minimizing technical disruptions experienced by their customers is critical to retain competitiveness, especially in the wake of stronger competition from OTT players.
Supervised and unsupervised algorithms can be used to detect an array of anomalies in network performance, including hidden ones that do not manifest themselves in explicit downtime. Furthermore, instead of confusing the NOC teams with a million alarms for ever-slight deviations, AI-powered predictive maintenance services can prioritize different incidents based on how soon they will hamper operations. Knowing when and why an incident occurs will improve the precision of your service planning and preventive measures.
As a result, this leads to the following benefits:
- Increased network availability and utilization
- Minimized and mitigated network outages
- Better data availability for O&M planning
- Higher staff productivity
- Reduced O&M costs due to optimized on-site dispatches schedule
- Higher service levels and customer satisfaction.
Klaudius Koschella from Vodafone Germany further explains the benefits of how predictive maintenance improved their operations:
How Anomaly Detection improves Operational Efficiency of Industrial Equipment
Predictive maintenance techniques vary in method, but ultimately, their effectiveness largely depends on the type and quality of data you can provide them with. Historical and current performance records alone do not always allow making accurate performance estimates, especially when it comes to complex industrial systems. That makes anomaly detection a crucial step for more effective PdM.
Anomaly Detection Algorithms Prevent Alert Creep
Merely installing sensors to gauge your equipment performance can lead to alert fatigue. After all, not every slight deviation about the threshold value signifies an imminent failure. Also, the threshold-based analysis of individual sensors does not communicate the full picture of the equipment performance.
In addition, the more sensors you install – the more monitoring will be required. Human operators may quickly get overwhelmed with the incoming volume of information and fail to recognize important patterns, amongst the less significant ones. Anomaly detection algorithms help process that growing volume of data and translate it into actionable insights.
Set Up Custom Threshold For Each Element and Sensor
Furthermore, over time a self-learning algorithm can help you identify better thresholds for different assets, based on feedback from the technicians. This lets you better configure your current setup, as well as minimize the hassle of setting up ultimate thresholds for new equipment.
Unsupervised Algorithms Can Function with Limited Data
Certain equipment parameters may be challenging or cost-prohibitive to measure. For instance, extremely high temperatures or inconsistencies in performance across a large fleet of similar industrial equipment.
Standard predictive maintenance technologies may fall short in this case, unlike AI-driven anomaly detection. “Intelligent” systems can run simulations and perform high accuracy data interpolation based on other parameters to compensate the lack of accurate historical data.
Effective Scaling for Additional Use Cases
A single dataset can be effectively re-used for several anomaly detection algorithms, meaning that you can cross-check the accuracy and attempt to devise even more insights from the information at hand.
For instance, data collected from temperature sensors on a wind turbine can be used to detect and predict:
- Efficiency of equipment performance under different conditions
- Material reaction to severe temperature conditions
- Performance changes due to icing.
Real-Time Intelligence
State of art anomaly detection algorithms can gauge the performance of several thousands of machines and report on anomalies within just a few minutes. They provide operators with real-time data intelligence, unlike predictive maintenance systems that provide a long-term outlook on the asset performance.
Conclusions
Effective predictive maintenance is virtually impossible to achieve without solid machine learning models and sufficient volumes of relevant data. The latter may be hard to obtain if you are just at the start of your digitization journey.
Thus, we advise starting with a phased approach, based on anomaly detection strategy. Set up your systems to collect sensor data and capture threshold-based alerts first. Learn what is your normal range of operating parameters. Then, move on to implement an anomaly detection system for capturing and interpreting deviations, and collecting a dataset of common failure patterns. Once the groundwork is done, you can connect a predictive analytics suit to obtain highly accurate predictions on your equipment performance.
Infopulse data science team would be delighted to consult you on the best strategy for implementing predictive analytics through a phased approach. For more data mature companies, we also propose a proprietory anomaly detection platform. Get in touch with us for more details!
![Generative AI and Power BI [thumbnail]](/uploads/media/thumbnail-280x222-generative-AI-and-Power-BI-a-powerful.webp)
![Data Governance in Healthcare [thumbnail]](/uploads/media/blog-post-data-governance-in-healthcare_280x222.webp)
![AI for Risk Assessment in Insurance [thumbnail]](/uploads/media/aI-enabled-risk-assessment_280x222.webp)
![IoT Energy Management Solutions [thumbnail]](/uploads/media/thumbnail-280x222-iot-energy-management-benefits-use-сases-and-сhallenges.webp)

![Carbon Management Challenges and Solutions [thumbnail]](/uploads/media/thumbnail-280x222-carbon-management-3-challenges-and-solutions-to-prepare-for-a-sustainable-future.webp)

![Automated Machine Data Collection for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-how-to-set-up-automated-machine-data-collection-for-manufacturing.webp)

