
How Data Fabric Helps Resolve DWH and Data Lakes Constraints
Such rapid growth of data consumption prompts business leaders to explore new approaches to procuring and operationalizing corporate intel. Data fabric, in particular, is one of the up-and-coming trends with strong prospects of becoming mainstream.
What is Data Fabric?
Data fabric is an emerging data architecture pattern that links together different data sources in a consolidated cloud environment. With the help of it, business applications, end-users, and data management tools can securely access data stored in any target location.
Think of data fabric as a technology “coating” stretched across your data assets to power seamless, secure access to disparate data storage systems, located on-premises, in the cloud, in a multi-cloud or hybrid environment. Such architecture assumes the usage of application programming interfaces (APIs) to enable two-way access to different types of business-ready data.
The purpose of data fabric is to improve:
- Data discoverability and access
- Metadata management
- Data quality and standardization
- Data reusability and cross-application access
In 2019, the average enterprise used over 1,295 cloud services. Among them, around 50 services were employed for business intelligence and data analytics specifically. The issue with such a growing portfolio of products is that amongst them, few can be interlinked with one another to exchange data, making it hard to access and re-use data stashed in a particular tool. As a result of such one-way integration, corporate data silo increases.
Data warehouse (DHW) and data lake technologies were originally designed to break those barriers between apps. However, business leaders often confuse the role of data fabric vs data lake. The former enables better connectivity — the latter merely serves as cloud-based storage, where data gets injected and then retrieved for further analysis.
Given the rapid growth of big data sources and volumes, as well as companies’ orientation towards becoming data-driven organizations, new approaches to data management are required.
Why Businesses Need to Adopt Data Fabric
Data-driven companies grow at a 30% faster rate than less analytics-focused peers. From anticipating complex market dynamics to better understanding customer intent and purchase drivers, there are a host of reasons why investment in analytics solutions pays off. In pursuit of positive results, business leaders, however, often overlook technical constraints and feasibility.
The modern company relies on a mix of legacy systems and emerging cloud-native solutions built with new architectural approaches such as microservices. When it comes to data exchanges, such solutions do not operate on the same premises, both literally and figuratively.
Businesses today have three layers of data producing and consuming applications:
- Legacy (often on-premises) mono-function applications (for example, core financial app).
- Data warehouses as a “middleware” repository for storing and organizing some data, produced by local and connected apps.
- Cloud-based platforms and integrations, which serve an array of use cases at once and respectively require the most data.
Legacy software, for instance, may rely on older connectivity standards, such as EDI, AS2, FTP, SFTP, which can make data transfer slow and complex. Modern data apps, on the other hand, use ETL or ELT architecture — a one-way process of extracting and transforming data. Then it is loaded to a target host destination, such as a relational database, data lake, or DWH.
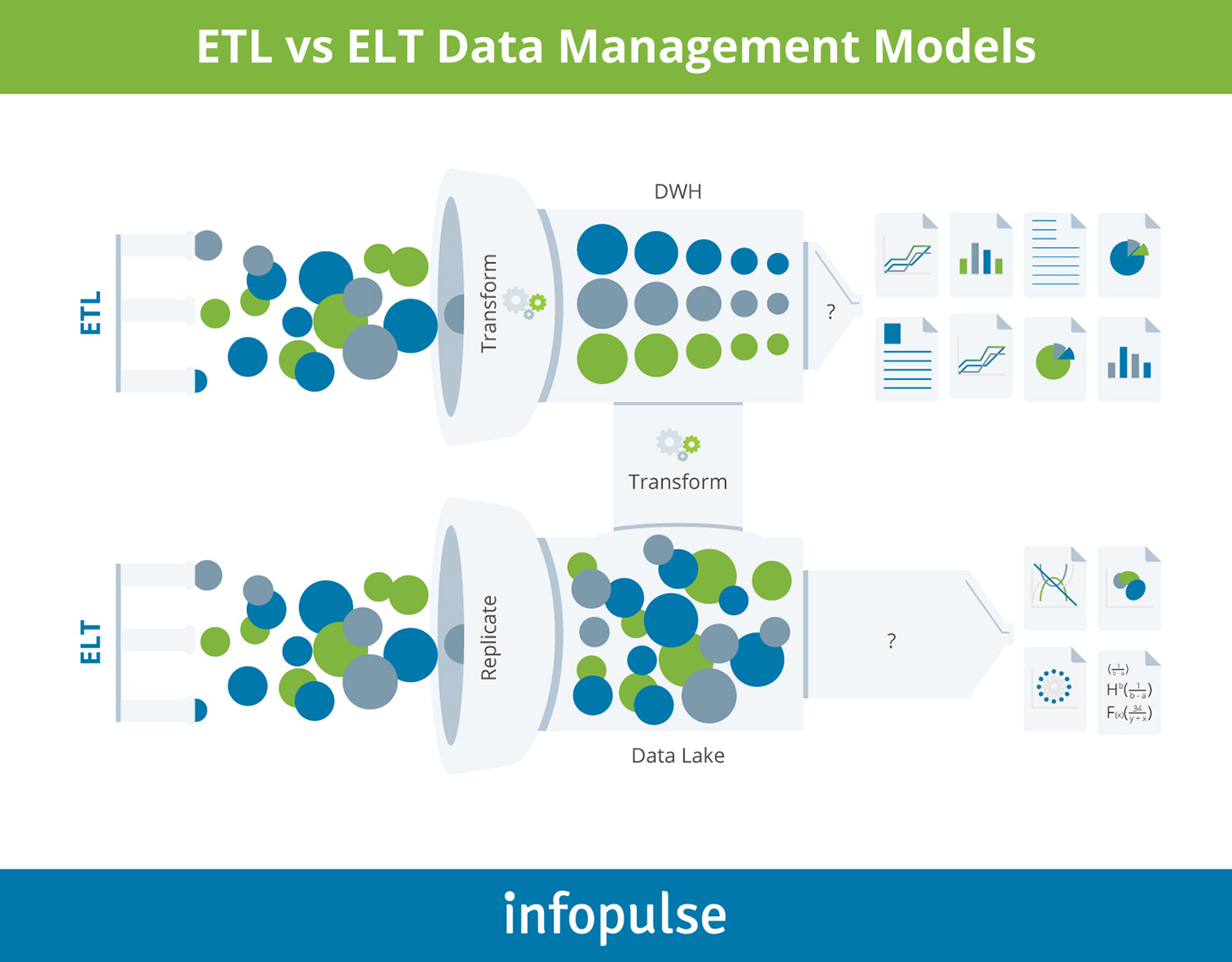
Data warehouse, such as SAP S4HANA, for instance, is a good solution for hosting structured analytics-ready data that can be injected into self-service BI tools or other user-facing analytics apps.
However, migration to the cloud and the platformization trend served as a springboard for a new type of offerings — cloud-based, extensible, multi-purpose business systems, matching to an array of needs at once, from customer relationship management to HR and accounting. Such platforms amass a ton of valuable data from connected systems (via APIs) and oftentimes “offload” it into a connected data lake — a scalable repository of all-purpose data in a raw state — or a data warehouse.
Establishing a secure and efficient connectivity between these three layers is an issue standing in the way of becoming a data-driven business.
That is the challenge data fabric was designed to solve. Unlike data warehouses and data lakes, data fabric does not force you to move data from one location to another. Instead, such an architecture establishes better data governance between the connected systems — be it an on-premises database, hybrid cloud-based analytics platform, or cloud-native DWH.
Common Data Management Challenges, Resolved by Data Fabric
Organizations today have no shortage of data, per se. Nonetheless, most have a hard time determining the optimal strategy or technological approach to support analytics activities:

In particular, the complexities extend to:
1. Data access. Apart from ensuring interoperability, companies also need to stay in control over access permission and compliant data usage. This can be hard to accomplish without proper oversight over a large number of users.
How data fabric helps. The technology programmatically enforces proper data governance practices. Not only does data fabric pave the way for accessing siloed intel, but it also helps standardize data formats, codify access permissions and usage rights, as well as provides visibility into how data is consumed by different services and users.
2. Data management and distribution. Just-in-time access to data is crucial for the efficient training of AI models such as neural networks, anomaly detection systems, and other predictive analytics solutions. In addition, hotkey self-service access to corporate insights is also important for the line of business leaders. Yet, few businesses can deliver the above. For instance, only 7% of banking leaders fully integrated analytics in their operations.
How data fabric helps. Data fabric enables centralized data management, backed by respective governance policies. Moreover, such an architecture should be configured to ensure optimized data workload allocation to prevent unbalanced load distribution across your IT infrastructure, so that users and systems in any geographic location could access the required data at a fast speed with low latency.
Learn how we helped a financial organization build an SAP HANA-based predictive analytics solution for compliance reporting.
3. Data security. Due to the rising rates of cyberattacks and data breaches across industries, business leaders are understandably wary of giving third parties access to their data or integrating extra partners into their ecosystems. However, as BCG notes, competitiveness in the 2020s will be held by platform-based IT organizations, capable of orchestrating effective collaboration and data exchanges within the organization and outside of its borders.
How data fabric helps. As an extra layer, data fabric helps establish standardized security policies for all connected APIs and ensure homogenized protection across different end-points. Then manage their enforcement from one interface. In fact, data fabric can be built using the Zero Trust Model principles to enact continuous evaluation of user’s access credentials and data usage patterns.
4. Regulatory compliance. Nearly every industry was affected by the European GDPR act. Highly regulated industries such as finance, telecom, and healthcare, among others, also face specific constraints to customer data usage. As a result, leaders often abandon their analytics projects because isolating sensitive data assets can be costly and operationally difficult.
How data fabric helps. First of all, data fabric allows establishing unified standards for transforming and using data. Secondly, the architecture can be configured to enable effective data traceability — a factor GDPR provisions require, for example. By knowing where your data rests, how it is stored, and who uses it, you could stay atop the changing compliance requirements, while still using a greater portion of available data.
5. Technology constraints. Earlier decisions around data storage and data management architecture can affect the future use of certain analytics tools. For instance, SAP data storage and analytics solutions run seamlessly on Azure due to the companies’ strategic partnership. Integrating another cloud provider into the mix or attempting to integrate an on-premises system may prove to be less technologically feasible without radical interventions. Respectively, many data sources remain untouched and data transformations getpostponed.
How data fabric helps. Data fabric is a technology-agnostic solution, so to speak, aimed at bringing together heterogeneous systems. Apart from acting as a “connector”, the fabric also ensures faster data transfer and provides scaling in and out capabilities. Therefore, you do not have to worry about optimal resource provisioning across multiple assets. Instead, you manage and control resource distribution for all workloads from a single interface.
Why Data Fabric is Complementary to DWH and Data Lakes
Data warehouses and data lakes each have their own merit. Data fabric is not meant to replace either option, but rather augment both to strengthen your connectivity.
Business leaders who already operate DWHs and have experience with data lakes are aware of the underlying constraints.
For data lakes, these include:
- “Swamping” — the tendency to use this storage space as an offload destination for every type of data available without further consideration of its value.
- Lack of data strategy and governance, which often results in data swamps, as well as high cloud computing costs and potential compliance issues.
- Low technological maturity for effectively supporting data lake architecture.
For data warehouses the common constraints are:
- Expensive data transformation and cleansing, which delays the access to analytics-ready intel, as well as reduces the scope of usable data sources.
- Higher operational costs, compared to data lakes, in terms of data transformation and storage costs.
- Limited scalability and lower querying speed, due to the technological nature of this solution.
Data fabrics architecture bridges the connectivity between data lakes, data warehouses, and any type of application, which obtains data from them. In addition, it prompts business leaders to re-assess their management approaches and establish consistent practices for data usage, as well as rebalance the costs by leveraging different data storage solutions.
Contact Infopulse to learn more about data fabrics architecture and novel approaches to managing corporate data securely.
![Carbon Management Challenges and Solutions [thumbnail]](/uploads/media/thumbnail-280x222-carbon-management-3-challenges-and-solutions-to-prepare-for-a-sustainable-future.webp)

![Automated Machine Data Collection for Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-how-to-set-up-automated-machine-data-collection-for-manufacturing.webp)


![Pros and Cons of CEA [thumbnail]](/uploads/media/thumbnail-280x222-industrial-scale-of-controlled-agriEnvironment.webp)

![Data Analytics and AI Use Cases in Finance [Thumbnail]](/uploads/media/thumbnail-280x222-combining-data-analytics-and-ai-in-finance-benefits-and-use-cases.webp)
![Data Analytics Use Cases in Banking [thumbnail]](/uploads/media/thumbnail-280x222-data-platform-for-banking.webp)
![Digital Twins and AI in Manufacturing [Thumbnail]](/uploads/media/thumbnail-280x222-digital-twins-and-ai-in-manufacturing-benefits-and-opportunities.webp)