
How to Reduce Cloud Waste with AWS Auto Scaling?
The service offers an intuitive interface that makes it easy to create scaling plans for various resources, including EC2 instances and Spot Fleets, Amazon ECS tasks, Amazon DynamoDB tables and indexes, and Amazon Aurora Replicas. Its main features include:
One of the reasons for high costs in cloud adoption is cloud waste. This cost category affects the TCO and operational expenses throughout the cloud solution lifecycle. 42% of respondents consider escalating costs the top reason for moving workloads back to on-premises infrastructure from the cloud.
In this article, we will focus on Amazon Auto Scaling – a tool to address cloud waste issues effectively for applications based on Amazon Web Services. Find out how to manage the cloud resources effectively, what approach to choose based on specific technical requirements, and how to adopt AWS Auto Scaling in 3 steps.
What is AWS Auto Scaling?
AWS Auto Scaling is a robust service by Amazon Web Services (AWS) that helps automatically manage and adjust the capacity of your AWS resources to maintain optimal performance and cost-efficiency for your applications. It allows defining scaling policies and utilizing predictive scaling to ensure the right amount of resources is used in the system, both under-provisioned and over-provisioned.
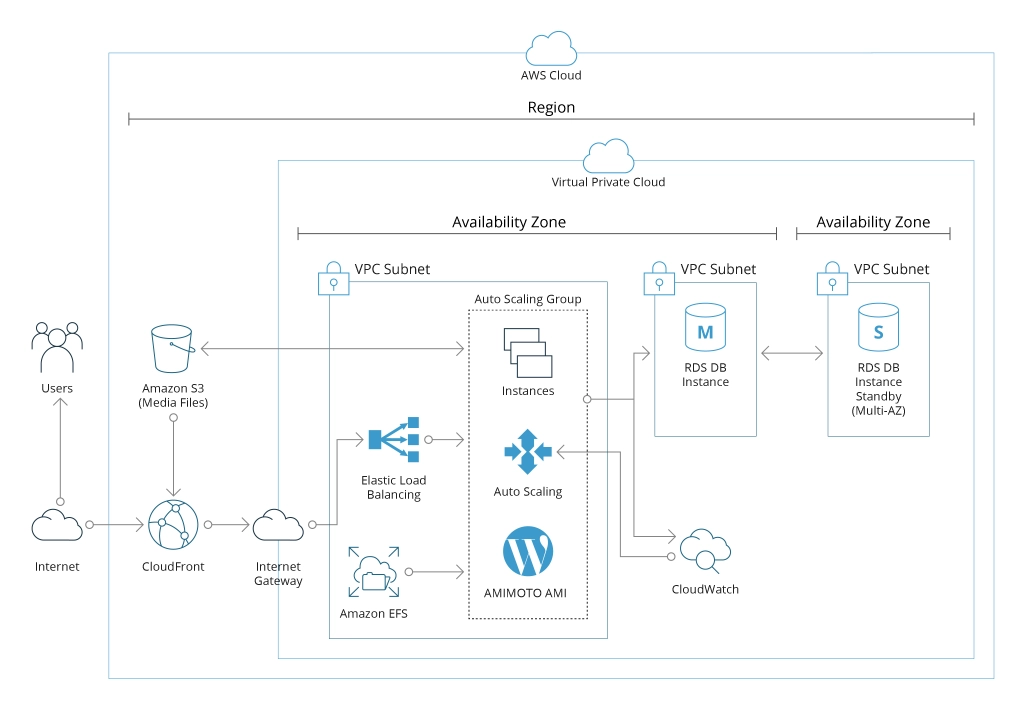
The service offers an intuitive interface that makes it easy to create scaling plans for various resources, including EC2 instances and Spot Fleets, Amazon ECS tasks, Amazon DynamoDB tables and indexes, and Amazon Aurora Replicas. Its main features include:
- Unified scaling: Setting up automated scaling for all scalable resources used to run your application from a single interface.
- Automatic resource discovery through the environment with no need to manually identify the resources to scale.
- Built-in scaling strategies: You can opt for one of three predefined strategies focused on optimizing costs, performance, or balancing both. It is also possible to use the custom target parameters for a scaling strategy fully tailored to the project needs.
- Predictive scaling: The tool can predict future traffic fluctuations and provision the proper number of EC2 instances to address the forecasted changes.
- Transparent management: Amazon Auto Scaling creates target-tracking scaling policies for all resources in the scaling plan. Additionally, it provides alarms that trigger scaling adjustments for each resource when necessary.
- Smart scaling policies: The tool continually computes the necessary scaling adjustments to increase or remove capability as required to maintain your target metrics.
Amazon Auto Scaling is available for free for AWS customers to manage the AWS resources that their projects run on. From the business perspective, it is a powerful optimization tool to ensure the appropriate cloud resources are used, enhance cost management, and automate their scaling.

When Does Your Business Need Amazon Auto Scaling?
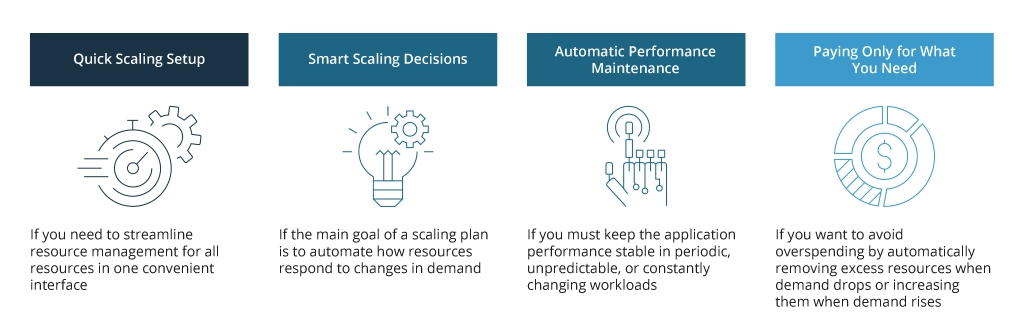
There are three primary drivers for adopting Amazon Auto Scaling — improving the capacity of your application, its performance, or optimizing costs by reducing cloud waste. It is not about scaling all network resources: AWS Auto Scaling is intended for scaling resources required for application functioning, such as virtual machines, databases, and others.
Here are the technical cases when AWS Auto Scaling brings tangible value:
- Cost optimization: Auto Scaling allows you to align resource allocation with actual demand with no waste of cloud resources.
- Managing fluctuating workloads: AWS Auto Scaling ensures automatic adjustments to handle regular workload changes. For instance, you can set up an hourly system for managing data loads that differ at different times.
- Seasonal peaks: If your application experiences seasonal spikes in usage (during holidays or specific events), accommodate the increased data loads during these periods and scale down afterward to save costs automatically.
- Improved performance: Automatic resource scaling leads to better application performance by ensuring the right amount of resources are available at any given time. In this way, you prevent under-provisioning that leads to performance bottlenecks.
- Enhanced reliability: By spreading workloads across multiple instances automatically, you significantly reduce the downtime risks. Also, Auto Scaling detects the EC2 instance termination due to a system error or hardware failure and automatically replaces it to prevent downtime.
- Reduced manual intervention: Automatic capacity management eliminates manual metrics monitoring and capacity adjustments around the clock, reduces human error risks, and lowers human labor costs.
- Handling unpredictable latency: Auto Scaling ensures you can cope with the increased demand with no service interruptions. For example, if data loads suddenly surge due to marketing campaigns or some viral content.
- Resilience: The tool allows scaling up as your business expands without completely overhauling your infrastructure.
The essence of adopting AWS Auto Scaling is its dynamic, future-proof adjustability to the changing workloads. Compared to manual scaling, this tool implies significantly less human effort due to the automation of monitoring and alerting about changes. As a result, you get an efficient resource balancing tool capable of satisfying the application demand changes in time.
Components of Amazon Auto Scaling
Automatic management of the resources from the server cluster in AWS Auto Scaling is provided through various mechanisms. They give flexibility in terms of configuring CPU and other resource utilization levels. When the threshold is reached, the tool automatically upscales resources. Similarly, if the load goes below the predefined threshold, the system automatically scales down the default configuration level.
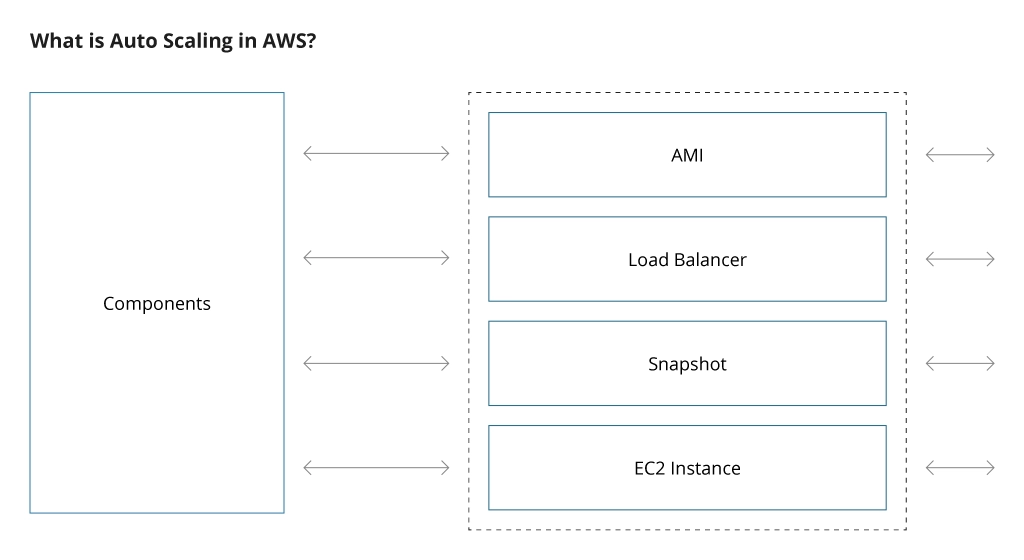
The components involved in Amazon Auto Scaling, include the following:
- AMI (Amazon Machine Image): It is an image of an EC2 instance configured for running your applications. It is an identical executable image of the system that can be used to create new images and launch new instances for scaling purposes.
- Load Balancer: This element handles the division of workloads among instances. It can automatically define the loads and redirect requests based on the predefined rules to the instances with less load. Classic load balancers spread the traffic equally to all enabled instances. Application load balancers redirect the traffic based on a set of predefined rules. The choice depends on specific project requirements.
- Snapshot: This is a copy of data on your instances. In the case of an incremental snapshot of the EC2 instance, it captures only data blocks modified during the previous snapshot.
- EC2 (Elastic Compute Cloud) Instance: A virtual server in Elastic Compute Cloud (EC2) used for deploying applications on AWS infrastructure. Access to a virtual server is done through an SSH connection to install various app components.
- Auto Scaling Groups: It is a group of EC2 instances that is created from a common Amazon Machine Image (AMI). They usually share similar configurations and automatically adjust the number of instances within the groups based on the demand and ensure that the group maintains a specified level of capacity and performance.
All these elements are set up to enable AWS Auto Scaling. First, an AMI of a user’s server should be created. After it has been created, the configuration is launched. During the configuration, the appropriate instance type is selected based on requirements. Then, an auto-scaling group is created after the configuration has been launched.
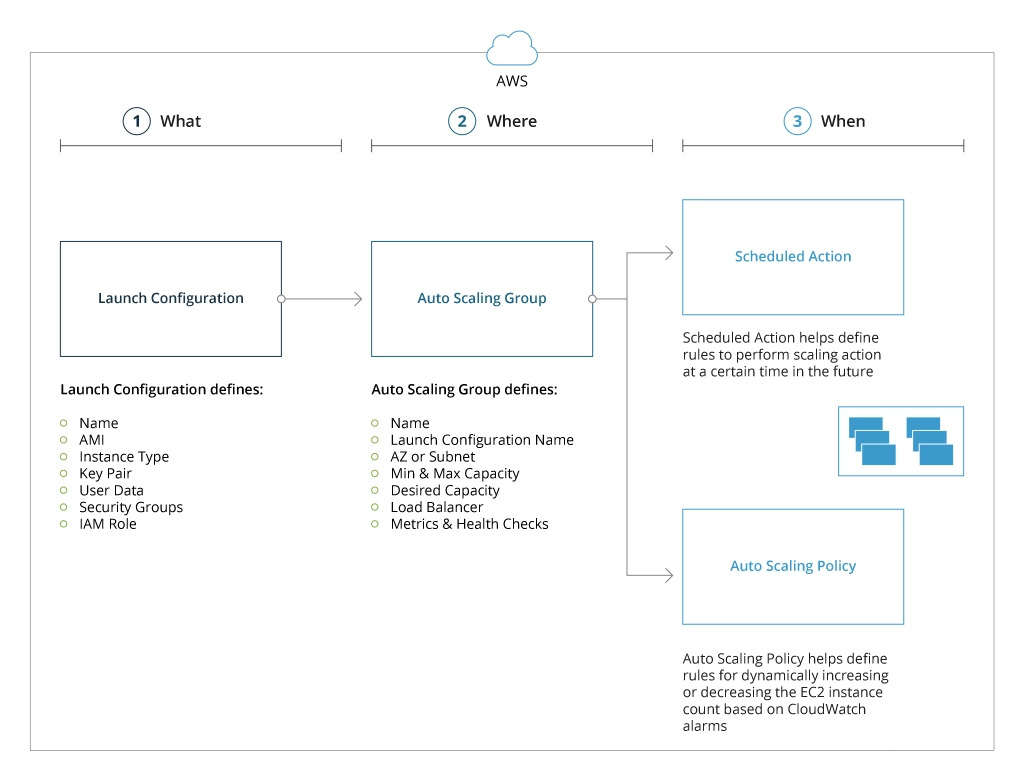
When the workloads increase, the AWS Auto Scaling service initiates creating new EC2 instances with a similar configuration to the server, replicating settings from AMI. If the traffic is low, the excess instances will be removed. With every new instance created, the load balancer divides workloads among them.
Scaling Strategy: Which One to Choose?
AWS Auto Scaling can be configured to properly scale the application resources based on availability, cost, or a balance of both:
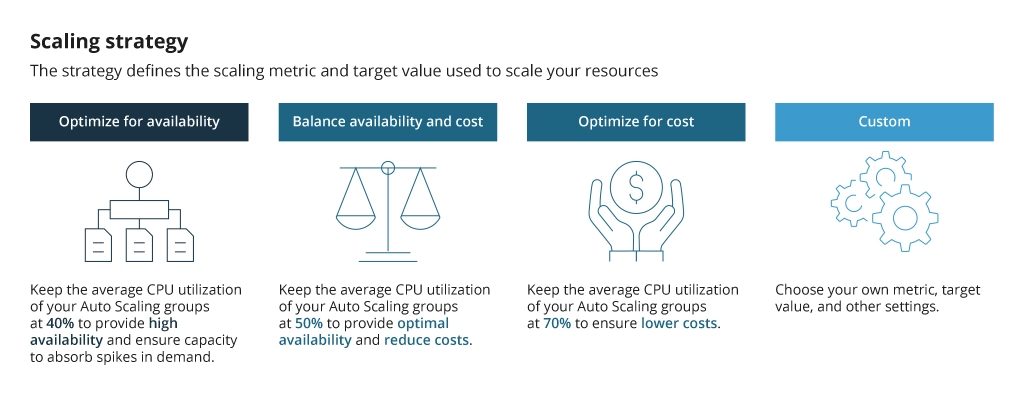
When choosing your scaling strategy, you can also select one of the scaling types available:
- Reactive: In this scaling method, the number of instances is changed manually in response to specific workload changes. For example, in cases where we have latency when the response time exceeds a certain limit, we adjust the capacity (CPU or memory). Compared to other scaling approaches, reactive scaling involves more effort and thankfully, is less popular in modern projects.
- Scheduled: It involves automatic scaling based on a particular schedule. For instance, if an app is hardly used at the weekends, you can reduce the number of EC2 instances from five to two for the period from Friday night to Monday morning.
- Dynamic: Dynamic scaling automatically adjusts the quantity of EC2 instances in response to signals from CloudWatch alarms. This approach is typically used to address fluctuations in traffic, especially when it's unpredictable. For example, if the CPU load exceeds 60%, one more EC2 instance is added. If the CPU gets lower than 40%, the EC2 instance is removed. Dynamic scaling is considered one of the most efficient methods, which takes comparatively longer to set up yet requires less effort in management and maintenance.
- Predictive: This method utilizes machine learning algorithms to forecast the optimal number of instances based on anticipated future traffic patterns. It makes sense to use this approach when workloads are expected to follow a predictable pattern.
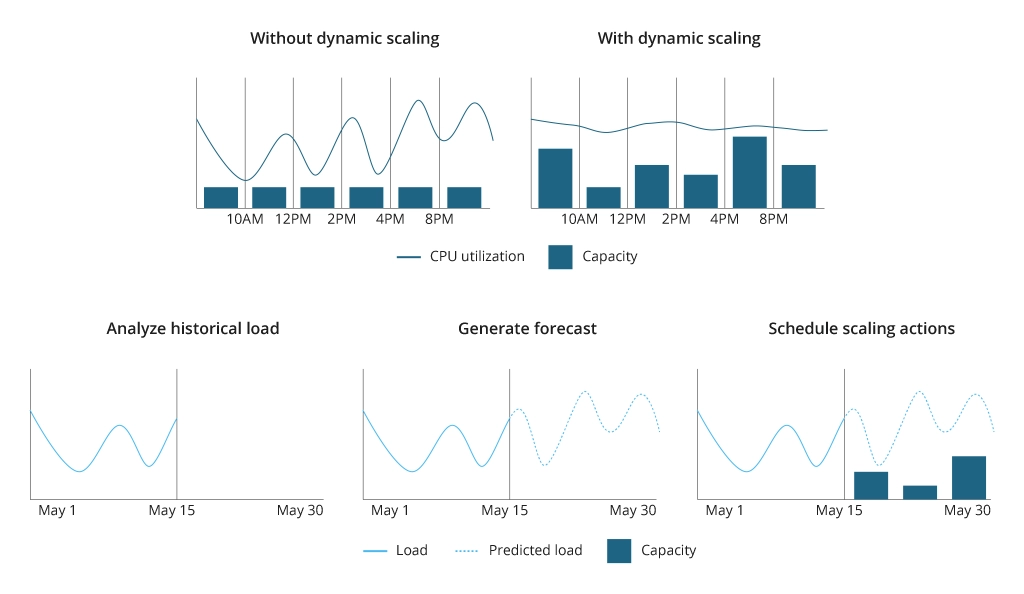
All scaling methods help to optimize the spending of cloud resources, at the same time maintaining the target performance parameters. All of them are aimed at minimizing the resource waste, which reduces the overall project costs. Each approach meets specific application requirements and the character of workload fluctuations, which define the choice of the most suitable scaling method.

Adoption Roadmap for Amazon Auto Scaling
The implementation of Amazon Auto Scaling involves a series of steps to configure and manage all its elements according to the specific application requirements and business purposes. Here is a 3-step adoption roadmap to get started with Amazon Auto Scaling:
- Assessment and Planning
- Analyze the load metrics (CPU, timing, connection, etc.). For example, compare values for 30 days and define minimum and maximum values.
- Define scaling policies. In the case of weekly or hourly load peaks, you can choose scheduled scaling. For harder predictable changes, dynamic scaling is preferable.
- Select an Auto Scaling group configuration (create a new Launch Configurator or choose an existing one).
- Define maximum and minimum capacity. Set the minimum and maximum number of instances in the Auto Scaling Group to define the scaling boundaries.
- Implementation and Configuration
- Create an Auto Scaling Group by defining the desired capacity, launch configuration, availability zones, and other parameters.
- Configure scaling policies by specifying target tracking, step scaling, and scheduled actions.
- Define health checks to monitor the status of instances.
- Enable cooldown periods to prevent rapid, consecutive scaling actions (optional).
- Monitoring and Optimization
- Monitor your Auto Scaling Group: continuously monitor your group’s performance and the metrics that trigger scaling actions.
- Configure scaling alerts/notifications: use Amazon CloudWatch to set up alarms for key metrics to alert you when scaling events occur.
- Fine-tune scaling policies: review and adjust your scaling policies regularly to control your app’s behavior and performance changes.
- Test your setup: simulate scaling events or test your Auto Scaling setup on a staging environment to ensure your policies and settings work correctly.
- Adjust resource allocation: define minimum and maximum capacity limits to optimize resource allocation while getting more data about your application performance.
This adoption plan will help minimize cloud waste by ensuring your application functions reliably and can scale to the changing workloads accordingly.
Conclusion
Cloud waste is one of the core reasons for overspending and failure in cloud-based operations. Amazon Auto Scaling helps reduce cloud waste through:
- Efficient resource utilization
- Automatic scaling mechanisms to adjust the current and future workloads
- Automatic termination of unnecessary instances
- Instance lifecycle maintenance with timely health checks and failure detection
- Elastic load balancers to distribute workloads across instances
Infopulse is an official Amazon partner with certified expertise in providing professional cloud services and solutions on the AWS platform. Our specialists will help to set up AWS Auto Scaling correctly and choose the optimum scaling approach for your application specifics.

![AWS Cloud Storage [Thumbnail]](/uploads/media/thumbnail-280x222-what-aws-cloud-storage-solution-can-best-agree-with-your-business_.webp)
![FinOps: Key Principles and Benefits [thumbnail]](/uploads/media/thumbnail-280x222-cloud-cost-optimization-with-finops.webp)
![Security Stack [thumbnail]](/uploads/media/THUMBN~1.WEB)
![AWS migration strategy [thumbnail]](/uploads/media/thumbnail-280x222-aws-migration-strategy.webp)
![Big Data Platform on AWS [thumbnail]](/uploads/media/thumbnail-280x222-aws-data-platform-20230227.webp)
![Benefits of Cloud-Agnostic Strategy [thumbnail]](/uploads/media/thumbnail-280x222-cloud-agnostic-strategy-whats-in-and-how-to-act-to-get-tangible-business-value.webp)
![AWS Security Hub Integrations [thumbnail]](/uploads/media/top-security-solutions-to-integrate-with-aws-security-hub-for-soc-280x222.webp)
![Asset Management in AWS [thumbnail]](/uploads/media/thumbnail-280x222-how-to-enable-effective-asset-management-in-your-was-environment.webp)
![AWS Hybrid Cloud Solutions [thumbnail]](/uploads/media/thumbnail-280x222-hybrid-cloud-on-aws-benefits-and-use-cases.webp)
![Building AWS Security Hub [thumbnail]](/uploads/media/thumbnail-280x222-enterprise-guide-to-building-your-aws-security-hub.webp)
![DevSecOps on Azure vs on AWS [thumbnail]](/uploads/media/thumbnail-280x222-dev-sec-ops-on-aws-vs-azure-vs-on-prem_1.webp)

