
Data Storage Security: Best Practices for High Cyber-Resilience
Types of Data Storage to Protect
Data storage includes all the physical and virtual devices, used by your organization to preserve digital information. These include on-premises servers and cloud data platforms, as well as a number of hybrid scenarios (e.g., a combination of private and public clouds or on-premises data centers and cloud solutions).
On a lower level, data storage solutions can be categorized as:
- Data warehouses (DWH)
- Data lakes
- Databases (for structured data)
- Blob storage (for unstructured data)
If you are new to the topic of cloud data management, learn about the differences between data warehouses, data lakes, and data fabric from an earlier post.
Each of these systems contains important business and/or customer data. Loss, exposure, or damage of such data records can have negative business consequences, ranging from major compliance fines and reputational damage to loss of intellectual property and market share. Therefore, robust data storage protection is non-negotiable, especially for sensitive business or personal data.
Sensitive Data Security
Each organization owns confidential corporate information. It can be any type of trade secret that gives you an advantage over competition — be it unique intellectual property or a know-how manufacturing process. Such records must be properly protected against accidental exposure, targeted cyber-attacks, and insider threats. The latter are on the rise. Over half of companies experienced an insider threat in 2023, and 8% faced over 20 attempts.
Any type of financial records, supplier or vendor records, customer lists, marketing strategies, and unpublished patents are also examples of confidential information.
Personal data is the second most important asset to safeguard. Global data privacy laws like GDPR, CCPA, and HIPPA among others, mandate strong protection policies for personally identifiable information (PII).
PII is any type of data a third party can use to confirm an individual's identity. For example:
- Name and surname
- Home address
- Phone number
- IP address
- Date of birth
- Gender
- Ethnicity
Companies in many industries need to collect PII to render effective services — provide access to online banking, ensure smooth online order delivery, help book accommodations, and so on. Yet, they must also ensure proper protection of such records to avoid regulatory fines or worse — data breaches.
Hackers are well aware that businesses now have ample data reserves, many of which are poorly protected. By targeting data storage locations, hackers find it easy to get high-value data. A driver's license scan goes for $150-$160 on the Dark Web — and one successful hack can yield the threat actor hundreds of records.
In 2022, Pegasus Airlines suffered a major customer data breach, which exposed over 6.5 TB of sensitive data including flight charts, navigation materials, crew PII details, and some of the credentials for accessing even more sensitive corporate files. The root cause of this hack? This data was left in an unsecured AWS cloud storage location.
Finally, government data also requires appropriate protection levels. In democratic societies, many gov bodies maintain public records about recent procurement tenders, investment activities, and other financial activities. Likewise, many countries also maintain open government data portals, which provide access to public sector data on things like land value, building permits, economic activities, and more. Such portals often do not expose complete data as it may result in privacy breaches. However, they can be tampered with to obtain sensitive records.
Best Practices for Data Storage Security
Whether your data rests in the cloud or on-premises, the following data storage security practices are a must-do.
Apply Data Masking
Data masking method assumes the modification of original data in a way that makes it unrecognizable. As a result, you can create an inauthentic version of the sensitive data set, which is structurally similar to the real data. Without access to the original dataset, you cannot reverse engineer or roll back to the original data values.
By applying data masking, companies can use confidential corporate information and sensitive customer records for various purposes without increasing security or compliance risks.
The common use cases of data masking include:
- Software testing. Many applications require real-world data for testing, but using real records can increase security risks. By using masked data, software developers and QA engineers can test new systems without exposing sensitive information.
- Big data analytics. Data scientists can use anonymized datasets to identify general trends and discover new insights without risking any privacy violations. Many financial analytics use cases require data masking, for example.
- Cross-industry collaboration. Data exchanges have become a common element of strategic partnerships and joint ventures. To avoid any unnecessary exposure, many organizations choose to mask certain data elements before sharing them externally. Likewise, data masking allows the creation of public data sets and statistical databases.
Overall, data masking helps organizations to build granular data protection policies and ensure that their most critical records are well-protected.

This data protection storage method can also be easily applied to all types of data assets. For example, you can perform data masking in an on-premises database, and then transfer a masked data copy into a third-party environment. This approach is called static data masking.
Alternatively, you can use dynamic data masking (DDM) to avoid creating redundant data copies. In this case, data remains unmasked in an on-premises database, but anonymized on-demand whenever a sharing request comes in (e.g., a load request to a specific data warehouse or data lake).
The last approach is performing on-the-fly data masking aka performing shuffling in real-time as data travels between two environments. On-the-fly data masking is the most expensive to maintain, yet it is an important investment if you require continuous integration or synchronization of disparate data sets (e.g., when you are actively testing a new healthcare application.)
Implement Data Encryption
Data encryption involves encoding information in a way that only a party that has access to the encryption key can decipher. Encryption is a common method for protecting:
- Data in transit — such that is being exchanged by two applications, between an app and a browser, and so on.
- Data in rest — any records, stored in a database or in cloud storage. Storage encryption is often applied to backed-up and archived data.
For example, one of the best-known encryption methods is the Secure Sockets Layer (SSL) protocol, which creates a secure connection between a web server and a web browser to ensure safe exchanges of submitted details (e.g., login/pass information). Most of us know SSL as an https:// connection.
The two most common types of data encryption are:
- Symmetric encryption uses the same key for data encryption and decryption. Such shared keys require less computing power to operate and are more cost-effective to maintain. Data decoding also happens at a faster speed, often in several milliseconds. The downside is that if the shared key ends up in the wrong hands, the systems’ security will be compromised.
- Asymmetric encryption uses two separate keys for data encryption. A public key is used by everyone to send encrypted data and a private key one party can use to decrypt the message. This is a more expensive encryption method that requires more computing power and may not be the best choice for sending large data packets.
Overall, organizations should create policies to decide which data at rest and in transit needs to be encrypted. In most cases, an SSL/TLS connection will suffice for protecting online data transfers.
As for data at rest, it is best to apply role-level security for accessing different types of assets to avoid data confidentiality issues and mitigate other security risks. For example, Azure Storage and Azure SQL Database have encryption enabled by default for data at rest. You can then manage access permissions with authorized users via Azure Key Vault service. In addition, you can also apply data encryption for all Linux and Windows VMs, running on Azure.
Case in point: When migrating its data centers to the cloud, Metinvest Group leveraged the security capabilities of the Azure platform. The combination of Azure SQL Database, Azure AD, Azure Key Vault, and other available solutions helped Metinvest secure their cloud storage of over 240 TB of data.

Use Data Sensitivity Labels
In digital workplaces, data easily traverses between apps, systems, and users. Easy access to information is essential for promoting data-driven decision-making. Yet, haphazard data exchanges can also increase security risks.
To avoid accidental disclosures, use Microsoft Purview service — an easy utility for assigning sensitivity levels to different data assets and automatically monitoring their usage. With Microsoft Purview, you can run a full assessment of your current data estate with insights on the classifications found in your data, labels applied, glossary terms used, and so on. Such a scan is a great way to understand what type of data you have and then determine the optimal rules for its access/usage.
With Pureview, you can create custom rules for defining sensitive information classes and codify extra rules for users (e.g., add encryption to specific documents). The established rules will then automatically apply to all assets with this sensitivity label.
Sensitivity labels will automatically apply to all data stored in Microsoft 365 products and can be also extended to SharePoint, Teams, Power BI, and SQL databases. In addition, you can apply sensitivity labels to files and database columns in cloud storage locations like Azure Data Lake or Azure Files.
In this way, you can ensure that all sensitive data is properly classified and protected, wherever it rests or travels.
Establish Data Backup and Recovery Practices
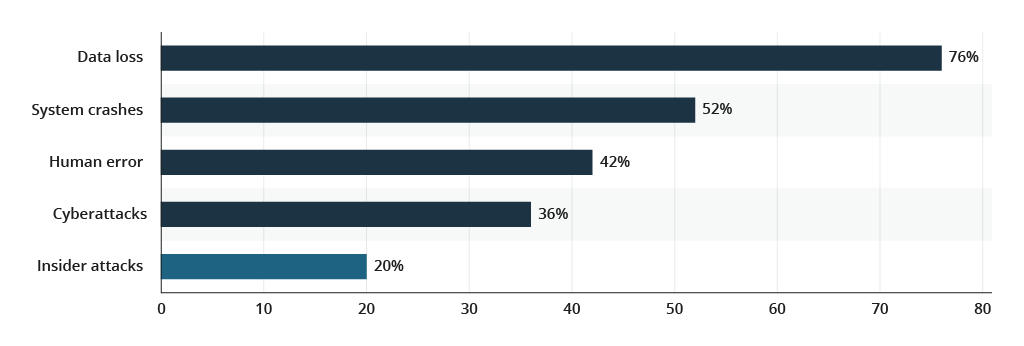
Regular data backups are the cornerstone security practice, which helps companies maintain strong business continuity even amidst lingering uncertainty. Backups help prevent data loss or degradation, which in turn, create operational downtime. On average, 76% of companies experience downtime because of data loss, which was caused by system crashes (52%), human error (42%), cyberattacks (36%) and insider attacks (20%).
To protect your company from the above scenarios, establish essential data backup practices:
- Apply the 3-2-1 rule for the most critical data. This means having 3 different copies of your data, of which two copies are in two different storage types, and one copy is kept offsite. Backups should be geographically distributed to ensure protection against local incidents and held both in the cloud and on-premises. Ideally, one physical backup should be stored outside of the corporate HQ in a secure location.
- Maintain a regular backup schedule. Because data gets updated multiple times per day, a fortnightly backup schedule is no longer enough. Important databases should be fully backed up once per 24 hours. You should also schedule differential database backups for databases, that process dozens of transactional records per hour (e.g., every 1, 4, or 6 hours depending on the data criticality). For example, a large online retail system or a retail banking system must be backed up every couple of hours to avoid any chances of data loss.
- Invest in immutable backups. Immutable storage is such, where data is stored in a WORM (Write Once, Read Many) state. Meaning this data cannot be edited or deleted. Immutable backups offer great protection against ransomware attacks since they prevent any type of overwrite or delete attempts. In addition, immutable storage is legally required by several regulations in the financial and healthcare industries, among others. Azure Blob Storage allows you to easily configure immutable storage locations for business-critical data with time-bound policies.
Read more about establishing effective business continuity and disaster recovery (BCDR) best practices.
Conclusions
Securing data storage is one of the main elements of high cybersecurity maturity. Full visibility into your data estates, granular access controls, regular backups, and application of data protection methods like data masking and encryption, are essential for the prevention of data loss, corporate breaches, and other cyber incidents.
![Main Benefits and Best Practices of Data Protection [thumbnail]](/uploads/media/thumbnail-280x222-data-protection.webp)
![Snowflake Data Cloud Overview [thumbnail]](/uploads/media/thumbnail-280x222-sowflake-data-cloud-its-benefits-and-capabilitie 9.webp)
![Defender for Endpoint [thumbnail]](/uploads/media/thumbnail-280x222-defender-for-endpoint.webp)
![Security Stack [thumbnail]](/uploads/media/THUMBN~1.WEB)
![Data Platforms on Azure [thumbnail]](/uploads/media/thumbnail-280x222-building-data-platforms-microsoft-azure.webp)
![How to Centralize Enterprise Security System [thumbnail]](/uploads/media/thumbnail-280x222-how-to-centralize-enterprise-security-system.webp)
![Guide to Security Automation [thumbnail]](/uploads/media/enterprise-guide-to-security-automation-280x222.webp)
![Cloud Data Platforms [thumbnail]](/uploads/media/the-many-faces-of-cloud-cata-platforms-280x222.webp)




